ソフトウェア工学におけるLLM vs LLM-based Agentsの性能比較についての論文を全文日本語訳しました
こんにちは、まっくす(@maximum_80)です。
昨今、生成AIのモデル進化、オーケストレーションツールなどの周辺プロダクト・プラットフォームの拡張、生成AIを活用したプロダクト事例など、この数年の生成AI活用は技術的にも目まぐるしい進化であることはみなさまご周知の通りかと思います。
そのような中で、昨今注目を集めているキーワードの一つに 「AGI(汎用人工知能)」 というものがあります。 AGIとは、特定の領域に特化するわけではなく、 さまざまなタスクや問題に対応できる能力を持っており、多様な知識やスキルを駆使して活動することが可能なAI さしておりまして、
- タスク実行力: 多様な知識やスキルを駆使し、さまざまなタスクや問題に対応できる能力
- 学習能力:AI自身が学習し新たな情報やデータを取り入れて自己進化する能力
- 意思決定能力:独自の判断基準を持ち、複雑な情報を分析し、最適な選択肢を選び出す能力
と位置付けられており、LLMの応用手法としても注目が集められています。
私自身も、今年の5月にシアトルに出張した際には、これまで生成AIは「特定のインプットに対して何かを出力する」という用途での活用が大半であったのに対して、今後は”Agent”として様々なタスク実行まで自律的におこなっていくような存在になっていくという世界観を改めて実感をしていたところでした。
そのような状況のなかで、つい先日、以下のような論文を見つけました。
[CL] From LLMs to LLM-based Agents for Software Engineering: A Survey of Current, Challenges and Future https://t.co/TGmSt4kXdl
— fly51fly (@fly51fly) August 6, 2024
- The paper provides a comprehensive survey on the application of large language models (LLMs) and LLM-based agents in software engineering. It… pic.twitter.com/v5bzaJb0Ub
生成AIの活用は、ソフトウェア開発現場にも注目がされており、GitHub Copilotの活用やCursorなど、AIによるソースコードの生成からレビュー、テストまで開発プロセスにおいて幅広い生産性の向上が期待されています。
この論文では、ソフトウェア工学における 要件工学、コード生成、自律的意思決定、ソフトウェア設計、テスト生成、ソフトウェア保守 の6つの観点において、様々な先行文献をもとに、LLMとLLMベースのエージェントによる作業、タスク、評価指標における類似点を比較した上で、効果の分析をしています。
また、これらの比較だけではなく、そもそものLLMやLLMエージェントの歴史や成り立ちについてや、ソフトウェア工学における応用など、基本的な概念が丁寧にまとめてあり、大変勉強になりました。
これから生成AIをソフトウェア開発に役立てていく上で、これは必読かもしれない、と考え、多くの方に読んでいただきたいと、日本語訳をいたしました。その上で、論文執筆者の方にお尋ねしたところ、ブログとして公開しても問題ないということでしたので、今回こちらの論文の日本語全訳を掲載させていただきます。
⚠️こちらの論文が非常に長文であるのと、スピード重視で生成AIを活用した翻訳であるため、一部翻訳が正しくない箇所があるかもしれません。その場合は改善をしていきたいと考えておりますので、適宜ご指摘いただけますと幸いです。また、[]で記載の注釈箇所の記載はできておりませんので、ご了承ください。
Acknowledgment
Dear Dr. Haolin Jin, Huaming Chen.
I find your paper to be highly valuable in the field of software engineering, especially in considering the application of LLMs and LLM-based Agents in software development environments. I sincerely appreciate your approval for the publication of the Japanese translation of your paper on this blog. Thank you very much.
- ソフトウェア工学におけるLLM vs LLM-based Agentsの性能比較についての論文を全文日本語訳しました
- From LLMs to LLM-based Agents for Software Engineering: A Survey of Current, Challenges and Future
- I. イントロダクション
- II. 既存研究と本論文の構成
- III. 予備知識
- IV. 要件工学とドキュメント化
- V. コード生成とソフトウェア開発
- VI. 自律学習と意思決定
- VII. ソフトウェア設計と評価
- VIII. ソフトウェアテスト生成
- IX. ソフトウェアセキュリティとメンテナンス
- A. LLMsのタスク
- 1. プログラム脆弱性
- 2. 自動プログラム修正(Automating Program Repair)
- 実際的な効果の調査
- ラウンドトリップ翻訳 (RTT) を使用したプログラム修正
- C/C++ コード脆弱性に対するNAVRepairの応用
- MOREPAIRフレームワークによるパフォーマンス向上
- 自動修正システムPyDexの紹介
- 3. ペネトレーションテスト(Penetration Testing)
- PENTESTGPTによるペネトレーションテスト
- ジェネレーティブAIによるペネトレーションテスト
- システムの堅牢性評価(Robustness Evaluation)
- RITFISによる堅牢性評価
- B. LLMベースのエージェントのタスク
- C. 分析
- D. ベンチマーク
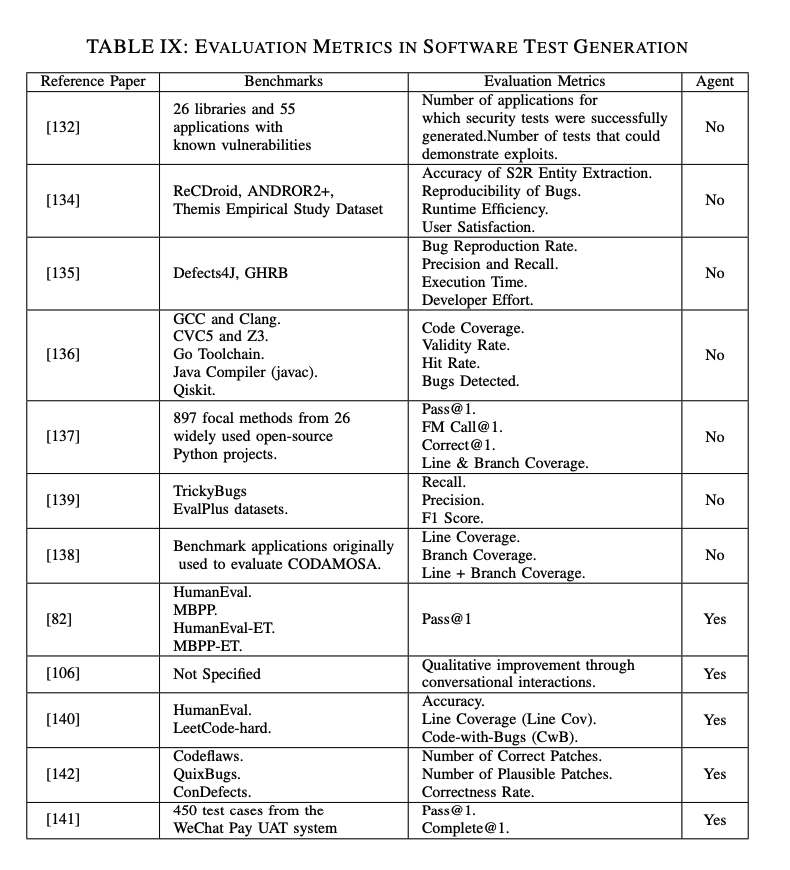
- E. 評価指標
- X. DISCUSSION
- XI. 結論
From LLMs to LLM-based Agents for Software Engineering: A Survey of Current, Challenges and Future
要約—大規模言語モデル(LLM)の台頭に伴い、研究者はソフトウェア工学などのさまざまな垂直領域での応用を探っています。LLMはコード生成や脆弱性検出などの分野で顕著な成功を収めていますが、多くの制限や欠点も示しています。LLMベースのエージェントは、LLMを意思決定と行動の中心として組み合わせ、自律性や自己改善の欠如などのLLMの固有の制限に対処することで、人工汎用知能(AGI)の可能性を秘めた新しい技術です。LLMをソフトウェア工学で使用する可能性を探る研究や調査が多数ありますが、LLMとLLMベースのエージェントの明確な区別はありません。LLMソリューションをその領域のLLMベースのエージェントとして資格化するための統一された標準とベンチマークはまだ初期段階です。この調査では、ソフトウェア工学におけるLLMとLLMベースのエージェントの現行の実践とソリューションを広範に調査します。特に、要件工学、コード生成、自律的意思決定、ソフトウェア設計、テスト生成、ソフトウェア保守の6つの主要トピックを要約します。これらの6つのトピックから、LLMとLLMベースのエージェントの作業をレビューし、タスク、ベンチマーク、および評価指標における違いと類似点を検証します。最後に、モデルとベンチマークを議論し、ソフトウェア工学における応用と効果の包括的な分析を提供します。この研究が、ソフトウェア工学におけるLLMベースのエージェントの境界を押し広げるための将来の研究に役立つことを期待しています。
索引用語—大規模言語モデル、LLMベースのエージェント、ソフトウェア工学、ベンチマーク、ソフトウェアセキュリティ、AIシステム開発
I. イントロダクション
ソフトウェア工学(SE)は、人工知能技術の助けを借りて研究開発が急成長しています。従来のニューラルネットワークや機械学習を利用したアプローチは、バグ検出、コード生成、要件分析などの様々なSEトピックを促進しました[1][2]。しかし、これらのアプローチは、特有の特徴工学の必要性、スケーラビリティの問題、様々なコードベースへの適応力の欠如など、いくつかの限界を示しています。大規模言語モデル(LLM)の台頭は、この分野に新たなソリューションと発見をもたらしました。GPT[3]やCodex[4]などのLLMは、コード生成、デバッグ、ドキュメント作成などの下流タスクにおいて顕著な能力を示しています。これらのモデルは膨大なトレーニングデータを活用して人間のようなテキストを生成し、前例のないレベルの流暢さと一貫性を提供します。研究によれば、LLMは知的なコードの提案を提供し、反復的なタスクを自動化し、自然言語の記述から全体のコードスニペットを生成することで、ソフトウェアプロジェクトの生産性を向上させることができます[5]。
しかし、その潜在能力にもかかわらず、LLMをSEに適用するには重大な課題があります。一つの大きな問題は、文脈の長さが限られていることです[6]。これにより、モデルが広範なコードベースを理解し管理する能力が制限され、長期的なやり取りで一貫性を維持するのが難しくなります。もう一つの主要な懸念は幻覚であり、モデルが一見もっともらしいが実際には間違っているか無意味なコードを生成することです[7]。これは、経験豊富な開発者が慎重にレビューしないと、バグや脆弱性を引き起こす可能性があります。さらに、LLMが外部ツールを使用できないことは、リアルタイムデータへのアクセスを制限し、トレーニング範囲外のタスクを実行することを妨げます。これにより、動的な環境での有効性が低下します。これらの制限は、SEにおけるLLMの適用に大きな影響を与え、また、LLMが生成したコードを正確性とセキュリティのために専門家が精査し改良する必要があることを強調しています[8]。複雑なプロジェクトでは、LLMの静的な性質が、変化する要件に適応したり、新しい情報を効率的に取り入れる能力を妨げることがあります。さらに、LLMは通常、外部ツールやデータベースと対話できないため、動的で進化するSEコンテキストでの有用性がさらに制限されます。
これらの課題に対処するために、LLMベースのエージェントが登場しました[9][10]。これらは、LLMの強みを外部ツールやリソースと組み合わせ、より動的で自律的な操作を可能にします。これらのエージェントは、取得補強生成(RAG)やツール利用などのAIの最新の進展を活用し、より複雑で文脈に応じたタスクを実行します[11]。例えば、OpenAIのCodexはGitHub Copilotに統合されており、開発環境内でリアルタイムのコード提案と補完を可能にします。静的なLLMとは異なり、LLMベースのエージェントは、エラーを特定して修正することでコードを自律的にデバッグしたり、効率や読みやすさを向上させるためにコードを積極的にリファクタリングしたり、コードベースとともに進化する適応型テストケースを生成することができます。これらの特徴により、LLMベースのエージェントは、従来のLLMよりも複雑で動的なワークフローを処理できる強力なツールとなります。
歴史的に、AIエージェントは事前定義されたルールに基づく自律的な行動や、相互作用から学習することに焦点を当てていました [13][14]。LLMの統合により、この分野に新たな機会が生まれ、より洗練されたエージェント行動のための言語理解と生成能力が提供されました。研究 [10] は、LLMベースのエージェントが自律的な推論と意思決定を行い、自然言語処理(NLP)から汎用AIへの進展を示すWS(World Scope)の第3および第4レベルを達成していることを示しています [15]。ソフトウェア工学において、LLMベースのエージェントは自律的デバッグ、コードリファクタリング、適応型テスト生成などの分野で有望です。これらの能力は人工汎用知能(AGI)に近づいています。本研究では、SE分野におけるLLMの統合とLLMベースのエージェントへの変換を概説する初めての調査を提示します。我々の調査はSEの6つの主要テーマをカバーしています:
- 要件工学と文書作成:ソフトウェア要件のキャプチャ、分析、文書化、ユーザーマニュアルおよび技術文書の生成。
- コード生成とソフトウェア開発:コード生成の自動化、開発ライフサイクルの支援、コードのリファクタリング、知的なコードの推奨。
- 自律学習と意思決定:SEコンテキスト内での自律学習、意思決定、適応計画の能力を強調。
- ソフトウェア設計と評価:設計プロセスへの貢献、アーキテクチャの検証、性能評価、コード品質評価。
- ソフトウェアテスト生成:ソフトウェアテストの生成、最適化、保守、単体テスト、統合テスト、システムテストを含む。
- ソフトウェアセキュリティと保守:セキュリティプロトコルの強化、保守作業の促進、脆弱性検出および修正の支援。
具体的には、以下の研究質問に取り組みます:
- RQ1:SEにおけるLLMおよびLLMベースのエージェントの最新技術と実践は何ですか?(第IV-IX章)
- RQ2:SEアプリケーションにおけるLLMとLLMベースのエージェントのタスクパフォーマンスの主な違いは何ですか?(第IV-IX章)
- RQ3:SEタスクにおけるLLMとLLMベースのエージェントの性能評価に最も一般的に使用されるベンチマークデータセットと評価指標は何ですか?(第IV-IX章および第X章)
- RQ4:SEでLLMを利用する際に使用される主要な実験モデルと方法論は何ですか?(第X章)
II. 既存研究と本論文の構成
A. 既存の研究
近年、大規模言語モデル(LLM)は主にプログラマーがコードを生成し、バグを修正するのを支援するために利用されています。これらのモデルは、ユーザーの入力に基づいてコードやテキストを理解し、完成させることができます。以前の調査論文では、Angela Fanの研究[8]などにおいて要件工学に関する詳述があまりありませんでした。論文によれば、ソフトウェアエンジニアは一般に、LLMを高レベルの設計目標に依存することに抵抗があります。しかし、プロンプトエンジニアリングやチェイン・オブ・ソート(COT)[16]などの方法を通じて、LLMが文脈解析と推論能力で顕著な改善を達成することで、要件工学への応用が徐々に増えています。表Iでは、要件工学におけるタスクを要約し分類しています。多くの研究が、要件の分類と生成のためにモデルを利用しています。収集は主に2023年後半から2024年4月以前に焦点を当てており、いくつかの論文は複数のタスクを扱っているため、表は収集した論文の正確な数を反映していません。
他の研究では、LLMのいくつかのSEタスクへの応用が調査されています[17][8][18]が、最近の研究開発を含む一般的なSE分野の広範なカバーは欠けています。さらに、これらの研究の主な貢献はLLMに焦点を当てていますが、LLMとLLMベースのエージェントの能力の違いは区別されていません。表IIでは、私たちの研究と他の研究との違いを要約し、この調査はLLMとLLMベースのエージェントの応用を6つのSEドメインにわたって明確に分析し、包括的で最新のレビューを提供します。以前の研究から、さまざまなアプリケーションやタスクにおけるLLMの性能は、モデルの固有の能力に大きく依存していることが明らかです[10]。さらに、以前の調査は広範な発行日範囲の論文からの発見を提示することが多く、異なるSEタスクにおけるLLMの内容の格差を生じさせています。例えば、要件工学の研究は比較的初期段階にあり、以前の調査ではこの分野の内容が乏しいです。LLMベースのエージェントの最近の台頭により、その能力と自律性が向上し、これらのギャップが埋められています。最新の研究に焦点を当て、LLMとLLMベースのエージェントを明確に区別することで、この調査はこれらの技術がSEにどのように適用され、新たな機会をもたらすかについての包括的で詳細な概要を提供します。
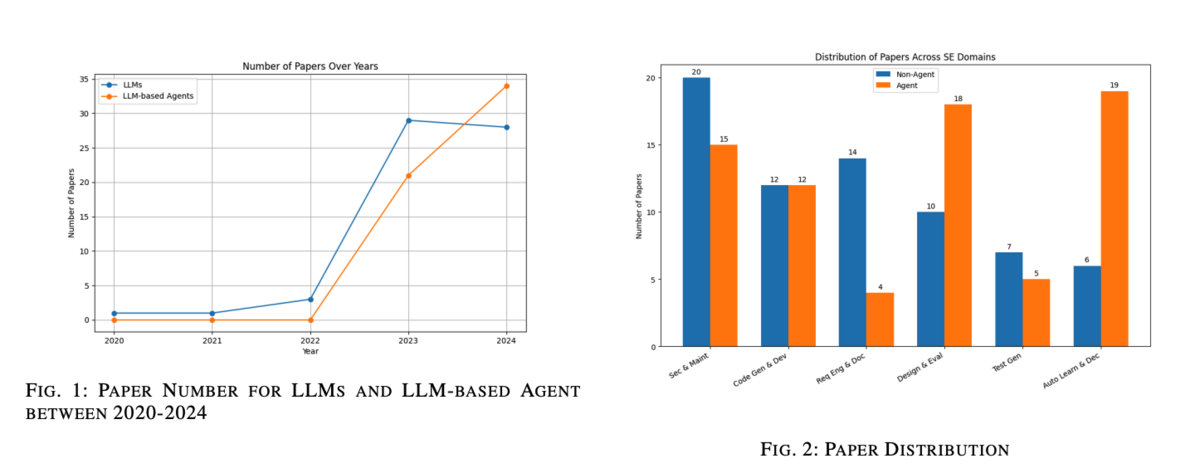
概要として、我々はこのトピックに直接関連する117本の論文を収集し、前述の6つのSEドメインをカバーしました(図1参照)。我々の分析は、LLMとLLMベースのエージェントの貢献を区別し、比較概観を提供するとともに、以前の調査の限界に対処します。LLMベースのエージェント分野の新規性と標準化されたベンチマークの欠如を考慮し、この研究は将来の研究を導く詳細なレビューを提供し、SEにおけるこれらの技術の可能性を明確にすることを目指しています。
B. 方法論
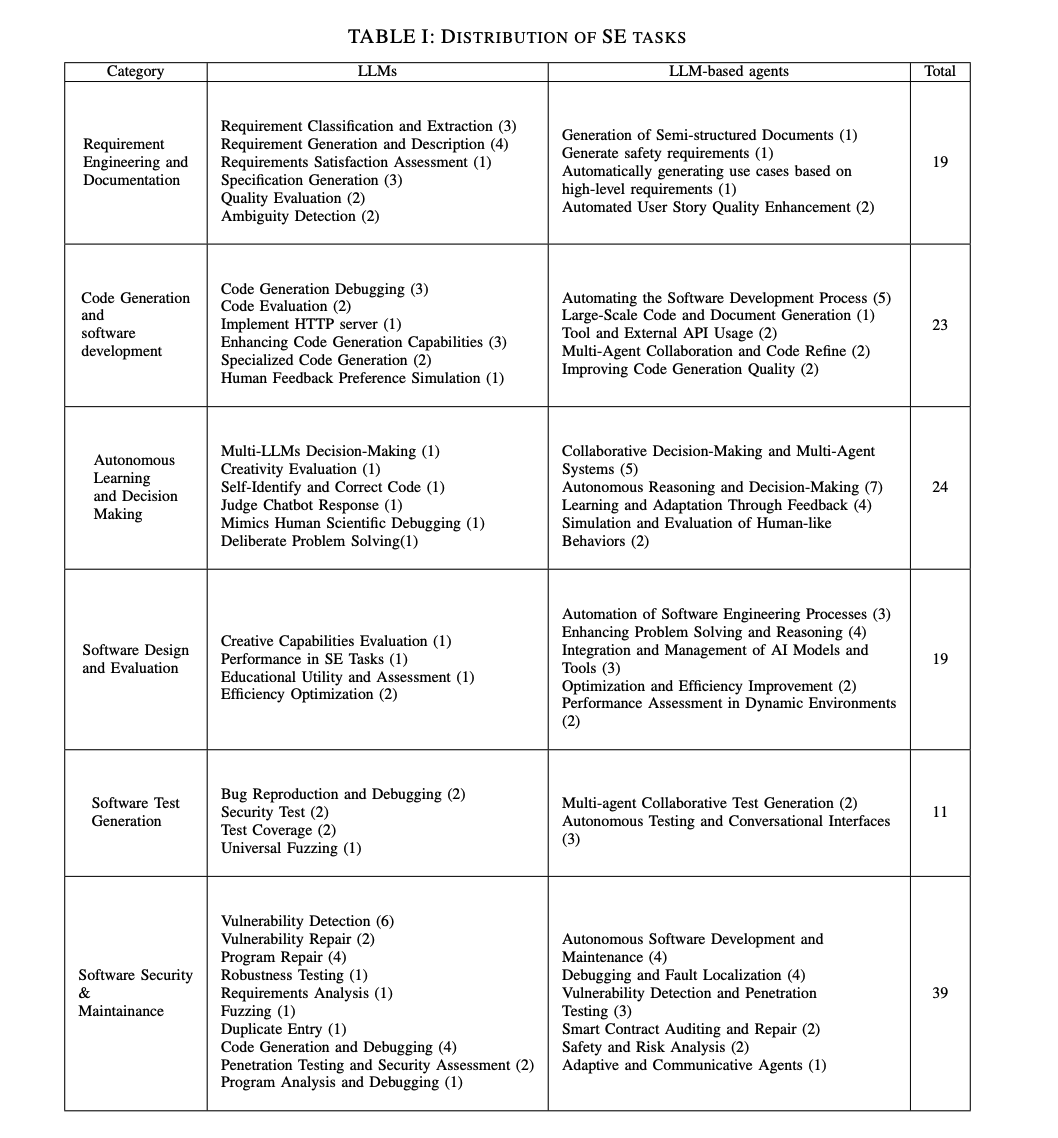
論文の収集プロセスは、主にDBLPおよびarXivデータベースを検索することにより行われました。2023年後半から2024年5月までの最近の研究に焦点を当て、このアプローチにより最新の研究を含めることができました。LLMに関連しない論文や7ページ未満の論文は除外しました。さらに、選択を洗練するために、表IIIのキーワードを使用してSE関連の論文を検索しました。その後、フォーマットエラーや学生プロジェクトを含む論文を手動で除外しました。重要な研究を捕捉するために、スノーボールサーチ技法も採用しました。全体で117本の関連論文を特定しました。図2は、これらの論文を6つのSEドメインに分けた分布とLLMベースのエージェント研究の割合を示しています。ただし、一部の論文は複数のカテゴリにまたがるため、図の文献レビューは合計で117本を超えています。
C. 本研究の全体構造
この論文の残りの部分は以下のように構成されています。第2章では、LLMおよびLLMベースのエージェントのアーキテクチャと背景を紹介し、RAG、ツールの利用、およびそれらのSEへの影響について概観します。第3章から第8章では、LLMおよびLLMベースのエージェント研究におけるデータセット、タスク、ベンチマーク、および指標を6つのSEドメイン全体で要約し比較する比較分析を行います。第9章は一般的な議論、第10章は最終的な結論です。
III. 予備知識
このセクションでは、大規模言語モデル(LLM)の基本概念を紹介し、それらのフレームワークの進化とアーキテクチャの概要を説明します。次に、LLMベースのエージェントについて議論し、単一エージェントシステムとマルチエージェントシステムの両方を探ります。また、これらのシステムの背景、それらの応用、およびソフトウェア工学の分野におけるそれらの区別についても説明します。
A. 大規模言語モデル
大規模言語モデル(LLM)は自然言語処理(NLP)と密接に関連しており、自然言語技術の歴史的発展は1950年代に遡ります。1950年から1970年の間に、特定のルールを用いた機械による言語対話生成の最初の試みが行われました。1980年代に機械学習技術が登場し、1990年代にはニューラルネットワークの導入によりNLPの新しい時代が始まりました[23]。これらの進展により、特にテキスト翻訳と生成技術の開発が大きく進展しました。Long Short-Term Memory(LSTM)およびリカレントニューラルネットワーク(RNN)の開発により、言語データの連続的な性質をより効果的に処理できるようになりました[24][25]。これらのモデルは、文脈の依存性の欠如に関連する課題を解決し、NLPの応用をさまざまな分野で強化しました。
2017年、Googleの研究チームによって「Transformer」と呼ばれる新しいフレームワークが導入されました[26]。自己注意メカニズムに基づくトランスフォーマーモデルは、言語モデルの効果を大幅に向上させました。位置エンコーディングの導入により、長いシーケンス依存性の問題を解決し、並列計算を可能にしました。2018年には、OpenAIがトランスフォーマーアーキテクチャに基づく生成的事前学習トランスフォーマー(GPT)[3]を開発しました。GPT-1の核心アイデアは、大規模なラベルなしテキストコーパスを用いた事前学習を行い、言語のパターンや構造を学習し、その後特定のタスクに適応させることでした。次の2年間で、OpenAIはGPT-2とGPT-3をリリースし、パラメータ数を1750億に増やし、文脈理解とテキスト生成の能力を示しました[27]。2023年にOpenAIが発表したGPT-4は、GPT-3.5の後継として重要なマイルストーンを表しています。GPT-4は約1750億のパラメータを維持しながらも、性能と多様性が大幅に向上しています。より洗練されたトレーニング技術とアルゴリズムの最適化を通じて、GPT-4は特に複雑なテキストや特殊な文脈の処理において、言語理解と生成の能力を強化しました。GoogleのPaLMやMetaのOPTなどの他の最新モデルと比較しても、GPT-4はマルチタスク学習とテキスト生成の論理的一貫性において際立っています。GoogleのPaLMモデルは540億のパラメータを誇りますが、GPT-4はより広範なNLPタスクにわたる優れた一般化能力を示しています[28]。オープンソースの大規模モデルでは、GPT-4に似たパラメータサイズを持つMetaのOPTモデルが直接競争相手となります。OPTはオープン性とアクセス性で優位性を持ちますが、創造的な執筆や複雑な問題解決などの特定の応用分野では、GPT-4が依然としてリードしています[29]。
B. モデルアーキテクチャ
大規模言語モデル(LLM)には一般的に3つのアーキテクチャが存在します。ここでは、エンコーダーデコーダーアーキテクチャを例に説明します。これは従来のトランスフォーマーモデルに代表され、6つのエンコーダーと6つのデコーダーで構成されています。データはまずエンコーダーを通過し、自己注意メカニズムを通じて順次特徴抽出が行われます。次に、デコーダーがエンコーダーによって生成された単語ベクトルを利用して出力を生成します。この技術は機械翻訳タスクで一般的に見られ、エンコーダーが一つの言語から単語ベクトルを処理し、デコーダーが正しい翻訳文を段階的に構築します。
最近の例としては、2023年にSalesforce AI Researchが発表したCodeT5+モデルが挙げられます[30]。このモデルは元のT5アーキテクチャを強化し、コードの理解と生成タスクのパフォーマンスを向上させることを目的としています。柔軟なアーキテクチャと多様な事前学習目的を組み込み、これらの専門的な領域での効果を最適化しています。この開発は、エンコーダーデコーダーアーキテクチャがますます複雑化するNLPの課題に取り組む能力を強調しています。
エンコーダーのみのアーキテクチャ
エンコーダーのみのアーキテクチャは、名前の通りデコーダーを除去し、データをよりコンパクトにします。このアーキテクチャはRNNとは異なり、ステートレスであり、隠れ状態に依存せずに入力処理を行うマスキングメカニズムを使用します。これにより並列処理速度が向上し、優れた文脈認識を提供します。代表的なモデルであるBERT(Bidirectional Encoder Representations from Transformers)は、エンコーダーの強力な特徴抽出能力と事前学習技術を活用し、テキストの双方向表現を学習して、感情分析や文脈分析で優れた成果を上げています[31]。
デコーダーのみのアーキテクチャ
トランスフォーマーフレームワーク内で、デコーダーは処理された単語ベクトルを受け取り、出力を生成します。デコーダーを直接利用してテキストを生成することで、テキスト生成やシーケンス予測などのタスクが加速されます。この高いスケーラビリティを持つ特性は自己回帰性として知られており、GPTのような人気モデルがこのアーキテクチャを使用する理由です。2020年には、GPT-3の卓越したパフォーマンスとその驚異的な数ショット学習能力が、デコーダーのみのアーキテクチャの大きな可能性を示しました[32]。モデルをゼロからトレーニングするために必要な莫大な計算コストと時間を考慮すると、多くの研究者は事前学習済みモデルを活用して研究を進めることを好んでいます。Meta AIによって開発された最も人気のあるオープンソースの事前学習済み言語モデルLLaMAも、デコーダーのみのアーキテクチャを採用しています[33]。先述の通り、この構造の自己回帰性とシンプルさが、モデルのトレーニングとファインチューニングを容易にしています。
C. 大規模言語モデルベースのエージェント
エージェントの概念は19世紀にまで遡り、人間と同等の知能を持つと考えられていました。過去数十年間で、AI技術の進化に伴い、特に強化学習の分野でAIエージェントの能力が大幅に向上しました。この進展により、AIエージェントはタスクを自律的に処理し、指定された報酬/罰則ルールに基づいて学習し、改善できるようになりました。注目すべきマイルストーンには、強化学習を活用して囲碁の世界チャンピオンを打ち負かしたAlphaGo[34]があります。
GPTの成功はこの分野をさらに推進し、研究者たちは大規模言語モデルをAIエージェントの「脳」として利用することを模索しています。GPTの強力なテキスト理解と推論能力のおかげです。2023年には、復旦大学の研究チームがLLMベースのエージェントに関する包括的な調査を実施し、その認識、行動、および認知について検討しました[10]。従来のLLMは、与えられた自然言語の説明に基づいて応答を生成するだけで、自立した思考や判断の能力が欠如しています。LLMベースのエージェントは、複数回の対話やカスタマイズされたプロンプトを使用してより多くの情報を収集し、自律的に思考し意思決定を行うことができます。
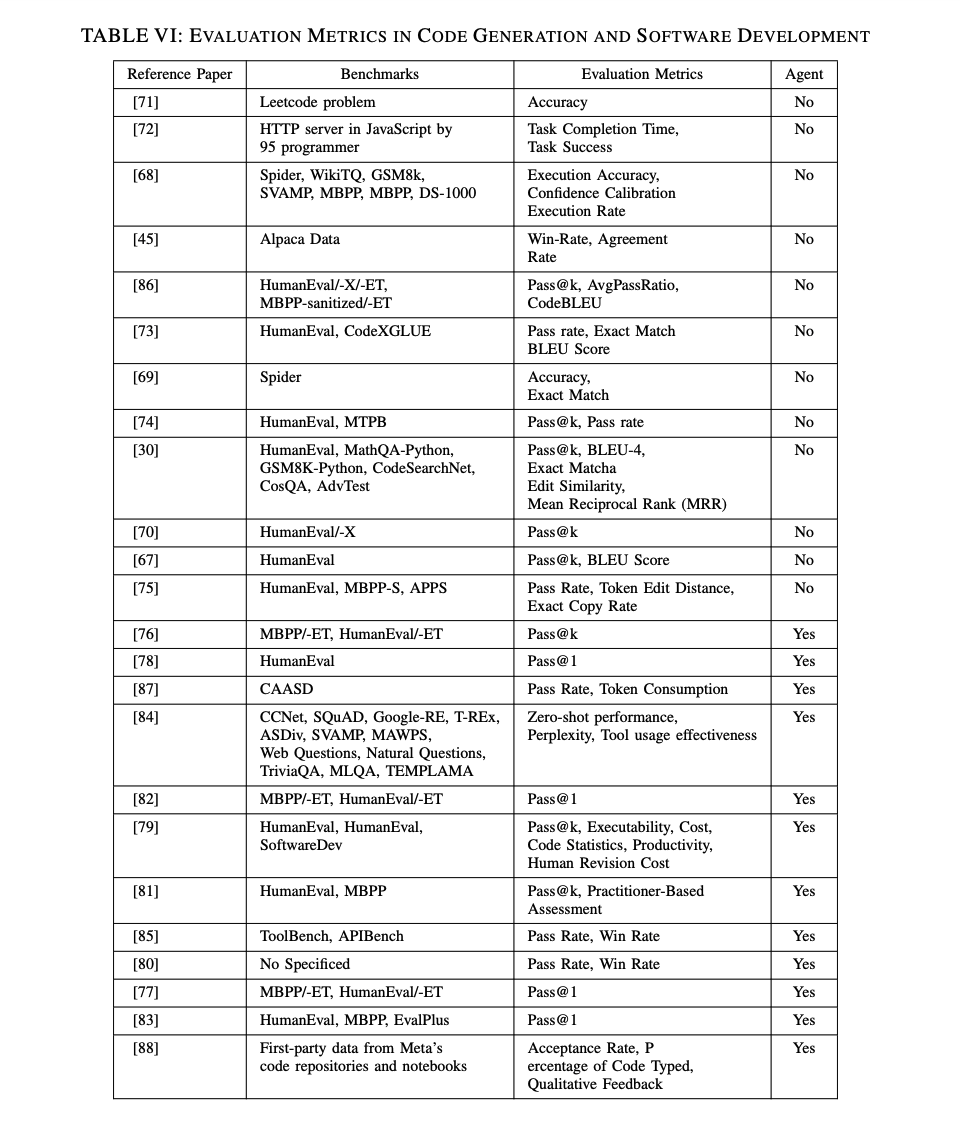
同じく2023年には、Andrew ZhaoがReActをプランニングフレームワークとして利用し、経験プールと組み合わせたExpeLフレームワークを提案しました[35]。これにより、LLMは過去の記録から洞察を抽出し、関連する後続のクエリに役立てることができます。LLMが以前の回答が間違っていた理由を分析することで、経験から学び問題を特定します。
同時に、LLMベースの具現化エージェントの応用も近年のホットな研究分野となっています。LLMベースの具現化エージェントは、LLMと具現化エージェントを統合した知能システムです[37]。これらのシステムは、自然言語を処理するだけでなく、物理的または仮想環境での認識と行動を通じてタスクを完了することができます。言語理解と実際の行動を組み合わせることで、これらのエージェントはより複雑な環境でタスクを遂行できます。この統合には、視覚データの処理と理解に視覚領域技術を使用し、環境内で最適な行動を取るために強化学習アルゴリズムを使用することが含まれます。これらのアルゴリズムは、報酬メカニズムを通じてエージェントが異なる状況で最適な決定を下す方法を学習させます。LLMはユーザーの指示を理解し、適切なフィードバックを生成する脳として機能します。
2023年には、Guanzhi WangがLLMベースのオープンエンドの具現化エージェントVOYAGERを導入しました[38]。このエージェントは、GPT-4を入力プロンプト、反復プロンプティングメカニズム、およびスキルライブラリと組み合わせて使用し、LLMベースのエージェントが自律的にMinecraftを学習しプレイできるようにし、ゲーム内で初めての生涯学習エージェントとなりました。
エージェントシステムは、判断を行うために大規模言語モデルに依存し、数ショット学習やマルチターンダイアログなどの技術を組み合わせてモデルの微調整を行います。しかし、データセットの不足やLLMベースのエージェントの新規性のため、多くの研究者はデータ拡張のためにさまざまな方法を採用しています。
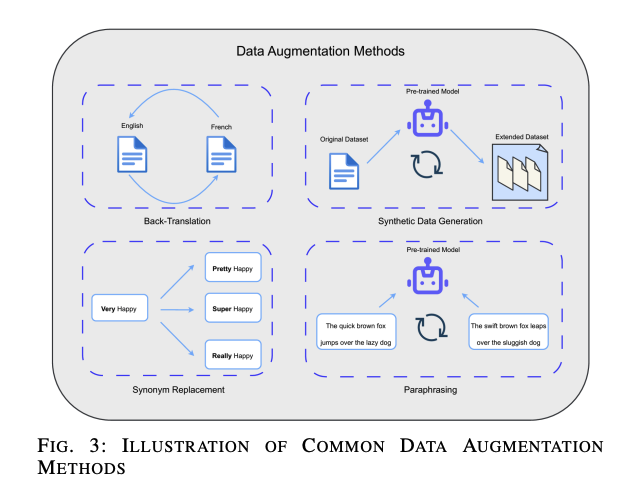
一般的なアプローチには以下が含まれます:
- 同義語置換:テキスト内の単語を同義語に置き換え、テキストの多様性を増やします。
- 逆翻訳:テキストを別の言語に翻訳し、再び元の言語に戻して、新しい文法構造や単語選択を持つテキストを生成します。
- パラフレーズ:手動または自動的に作成された、文脈は似ているが表現が異なる新しい対話を生成します。
- 合成データ生成:事前学習済みモデルを使用して合成データを生成します(図3参照)。
2023年、Chenxi Whitehouseは、LLMを用いてデータ拡張を行い、特に極めて限られたトレーニングデータ条件下で多言語常識推論データセットの性能を向上させる研究を行いました[39]。Dolly-v2、StableVicuna、ChatGPT、およびGPT-4などのさまざまなLLMを使用して新しいデータを生成し、元のデータに似た新しい例を作成することで、トレーニングデータの多様性と量を増やしました。プロンプトエンジニアリングは、LLMと効果的に対話するための重要なスキルとして言及されました。これらのプロンプトパターンを適用することで、ユーザーはLLMとの対話を効率的にカスタマイズし、高品質な出力を生成し、複雑な自動化タスクを達成できます。2023年、Jules Whiteは、ChatGPTなどのLLMとの対話を最適化するための一連の方法とパターンを紹介しました[40]。この研究は、プロンプトエンジニアリングを入力セマンティクス、出力カスタマイズ、エラー識別、プロンプト改善、相互作用の5つの主要分野に分類し、さまざまな問題に対応し、異なる分野に適応することを目的としています。
注目すべき技術の一つに、取得補強生成(RAG)があります。入力質問はインデックスライブラリの文書と類似度マッチングを行い、関連する結果を見つけようとします。類似文書が取得されると、それらは入力質問と共に整理され、新しいプロンプトが生成され、これが大規模言語モデルに入力されます。現在、大規模言語モデルは長文の記憶能力を持っていますが、多くの研究はRAGが廃れていないかどうかを探るためにGemini v1.5を「干し草の山の中の針」(NIAH)評価でテストしました[41]。しかし、コストや経費の観点から、RAGは依然として重要な利点を持ち(RAGはすべてのトークンを使用するよりも99%安価である可能性があります)、長文は応答性能に悪影響を及ぼす可能性があり、入力テキストが長すぎるとLLMが遅く応答します。したがって、LLMの文脈長の進歩はRAGの役割を完全に置き換えることはなく、補完関係にあります。
D. シングルエージェントとマルチエージェント
シングルエージェントシステムは、大規模言語モデル(LLM)の能力を活用してさまざまなタスクを実行します。これらのエージェントは通常、単一のLLMを使用してユーザーのクエリを理解し応答し、コンテンツを生成し、事前定義された指示に基づいて自動化されたタスクを実行します。シングルエージェントは、一般的な回答を受け入れるタスクや複雑な意思決定を必要としないシナリオでよく使用されます。例としては、カスタマーサービスのチャットボット、スケジュール管理のための仮想アシスタント、自動コンテンツ生成ツールなどがあります。
しかし、シングルエージェントは長い文脈入力を処理するのに苦労し、一貫性のない応答や関連性のない応答を生成することがあります。また、これらのシステムのスケーラビリティは、広範な知識や文脈を必要とするタスクに対処する際に限られています。この問題は、LLMが過度に長い情報を一度に完全に理解し分析できないため、長文の場合にしばしば悪化します。
大規模言語モデルの主な問題の一つは「幻覚」です[7]。幻覚とは、LLMが論理的かつ合理的に見える言葉でユーザーに提示する偽情報や定義を生成することを指します。LLMに関するほとんどの研究論文はこの問題を指摘しており、プロンプトエンジニアリングやツールの介入で幻覚の影響を軽減することはできますが、完全に排除することはできません。2023年には、Ziwei Jiが自然言語生成における幻覚についての詳細な研究を行いました[42]。この調査では、幻覚の定義や分類、原因、評価指標、軽減方法など、さまざまなタスクにおける幻覚現象に関する包括的な分析が行われました。
マルチエージェントシステムでは、複数のLLMや他のAIモデルを組み合わせて、より複雑なタスクを協力して実行します。これにより、個々のエージェントの限界を補完し合い、より高度な問題解決や意思決定が可能になります。
シングルエージェントシステムは、単一の大規模言語モデル(LLM)を使用して、ユーザーのクエリに応答し、コンテンツを生成し、事前定義された指示に基づいて自動化タスクを実行します。これらのエージェントは、一般的な回答を受け入れるタスクや複雑な意思決定を必要としないシナリオで使用されます。しかし、長い文脈入力を処理するのに苦労し、一貫性のない応答や関連性のない応答を生成することがあります。また、システムのスケーラビリティは、広範な知識や文脈を必要とするタスクに対処する際に限られます。この問題は、LLMが過度に長い情報を一度に完全に理解し分析できないため、長文の場合に悪化します。大規模言語モデルの主な問題の一つは「幻覚」であり、偽情報を生成することがあります。プロンプトエンジニアリングやツールの介入で影響を軽減することはできますが、完全に排除することはできません。
マルチエージェントシステムは、複数のLLMやエージェントが協力して複雑なタスクを効果的に処理します。これにより、個々のエージェントの限界を補完し合い、より高度な問題解決や意思決定が可能になります。2024年には、多くの研究者がマルチエージェントシステムを実験に採用しています[43][44]。
マルチエージェントシステムはシングルエージェントシステムの限界を以下の方法で克服します:
- 強化された文脈管理:複数のエージェントが文脈を維持し共有し、長い対話にわたって一貫性のある関連性の高い応答を生成します。
- 専門化と分業:異なるエージェントが特定のタスクや問題の側面に焦点を当て、効率と効果を向上させます。
- 堅牢性とエラー修正:協力するエージェントが互いの出力をクロスチェックし、エラーの可能性を減らし、全体的な信頼性を向上させます。
- 文脈の一貫性:複数のエージェントの協力により、長い対話における文脈管理が改善されます。
- スケーラビリティと柔軟性:これらのシステムは、専門エージェントを統合してスケールし、より複雑なタスクを処理できます。複数のエージェントによる分業により、コード生成の品質が向上します。
- 動的な問題解決:異なる専門知識を持つエージェントを統合することで、マルチエージェントシステムはより広範な問題に適応し、より正確なソリューションを提供できます。
E. ソフトウェア工学におけるLLM
近年、医療や金融などの特定の垂直分野への一般的なAIモデルの応用が進んでいます。ソフトウェア工学においても、従来のLLMよりも柔軟で知的な新しいAIエージェントが登場しています。これらのモデルはテキスト理解と生成に優れ、ソフトウェア開発や保守に革新的な応用を促進しています。
LLMは、コード生成、欠陥予測、自動ドキュメント作成などのタスクを支援することで、ソフトウェア工学に大きな影響を与えています。これらのモデルを開発ワークフローに統合することで、コーディングプロセスが簡素化され、人為的なエラーが減少します。LLMベースのエージェントは、意思決定や対話型問題解決機能を統合することで、基本的なLLMの能力を強化します。これらのエージェントは他のソフトウェアツールと連携して結果を理解・生成し、ワークフローを最適化し、自律的に意思決定を行ってソフトウェア開発の実践を改善します。
2023年には、Yann DuboisがAlpacaFarmフレームワークを導入し、LLMを用いて複雑な環境でのソフトウェアエージェントの行動をシミュレートしました[45]。さらに、2024年にはIslem Bouzeniaが自動ソフトウェア修復のためのLLMベースのツールRepairAgentを発表し、開発者が問題を修正する時間を短縮しました[46]。また、2023年にはEmanuele Musumeciが、各エージェントがドキュメント生成において特定の役割を持つマルチエージェントアーキテクチャを示し、複雑なドキュメント構造を扱う際の処理を大幅に改善しました[47]。
LLMは、ソフトウェアテスト、ソフトウェア設計、ソフトウェアセキュリティおよび保守などの新興分野でも優れた貢献をしています。
現在、LLMがLLMベースのエージェントと見なされるために必要な能力の包括的かつ正確な定義はありません。LLMのソフトウェア工学への応用が比較的広範であり、いくつかのフレームワークはすでに一定の自律性と知能を持っているため、この研究では、2024年上半期の主流の定義と文献に基づいて、LLMとLLMベースのエージェントの区別を定義します。本調査では、表IVの基準を満たす場合、LLMアーキテクチャをエージェントと呼ぶことができます。

IV. 要件工学とドキュメント化
要件工学はソフトウェア工学の中で重要な分野であり、ソフトウェア開発プロセスにおいて重要な役割を果たします。主なタスクは、ソフトウェアシステムがすべての関連するステークホルダーのニーズを満たすことを保証することです。プロジェクト開発における要件工学には多くのステップが含まれ、開発者はユーザーのニーズと期待を十分に理解し、ソフトウェアシステムの開発方向が実際の要件と一致するようにする必要があります。収集された要件は開発グループによって整理および評価されます。
要件仕様は、分析された要件を正式に文書化するプロセスです。仕様は正確で簡潔でなければならず、開発者がユーザーのニーズに合ったものを構築し、それが仕様と一致していることを確認するために要件の検証が行われます。要件工学には、ソフトウェア開発ライフサイクル全体にわたる要件管理も含まれます。開発者は、開発中に発生する変更を継続的に追跡、制御、および対応し、これらの変更がプロジェクトの進行と全体的な品質に悪影響を及ぼさないようにする必要があります。
A. LLMのタスク
要件工学の分野では、LLMは要件抽出、分類、生成、仕様生成、品質評価などのタスクを自動化し、強化する上で大きな可能性を示しています。
要件の分類と抽出は開発プロセスにおいて重要なタスクです。クライアントが複数の要件を一度に提示することが多く、開発者による手動分類が必要です。LLMの強力な分類タスク性能のおかげで、これを効率化する多くのフレームワークが開発されました。例えば、BERT事前学習言語モデルを利用したPRCBERTフレームワークは、分類問題を柔軟なプロンプトテンプレートを通じて一連の二値分類タスクに変換し、分類性能を大幅に向上させました[48]。PRCBERTはPROMISEデータセットでF1スコア96.13%を達成し、NoRBERT[49]やBERT-MLMモデル[31]を上回りました。
さらに、ChatGPTを用いた要件情報の検索も有望な結果を示しています。要件ドキュメントから情報を分類および抽出することにより、ChatGPTはゼロショット設定でベースラインモデルを上回る性能を発揮しました[50]。
表Iに示されるように、LLMを使用して要件や説明を自動生成することに関する文献や研究も多数存在します。
要件の生成と記述を自動化することで、要件抽出の効率と正確性が向上します。LLMは要件生成タスクで大きな可能性を示しており、例えば、ChatGPTを用いてユーザー要件を生成し収集する研究では、専門知識を持つ参加者がより効果的にChatGPTを利用できることが示されています[51]。この研究では、要件一致に対するLLMの出力を定性的に評価し、完全一致、部分一致、抽出された要件の関連性を含む基準に基づいて評価しました。結果はタスクの複雑さやユーザーの経験に依存しましたが、LLMが要件抽出を効果的に支援できることを示しています。
ソフトウェア要件仕様(SRS)の生成は、開発者が多くの時間を費やす重要なタスクです。ある研究では、反復プロンプティングと包括的プロンプトを使用して、LLMのSRS生成パフォーマンスを評価しました。GPT-4とCodeLlama-34bを用いた評価では、人間が生成したSRSが全体的に優れていましたが、CodeLlamaは特定のカテゴリで優れた結果を示しました[52]。
さらに、SpecGenフレームワークはプログラム仕様を生成するためにGPT-3.5-turboを使用し、プロンプトエンジニアリングとマルチターンダイアログを組み合わせて最適なバリアントを選択するヒューリスティック選択戦略を適用しました。SpecGenは、従来のツールであるHoudiniやDaikonを上回る70%のプログラム仕様を生成しました[53]。
プロンプトパターンの設計は、要件抽出やシステム設計のタスクにおいてLLMの能力を大幅に向上させることができます。ある研究では、13のプロンプトパターンをカタログ化し、それぞれがソフトウェア開発における特定の課題に対処することを目的としています[55]。
LLMは、自然言語要件の欠落部分を検出し補完することで要件の完全性を向上させることができます。ある研究では、BERTのMasked Language Model(MLM)を使用して、自然言語要件の欠落部分を検出し、82%の精度で補完しました[56]。
また、LLMは要件ドキュメントの曖昧性検出にも応用されており、文書の明確さを向上させ誤解を減らすことができます。研究では、BERTとK-meansクラスタリングを使用して、同じアプリケーションドメイン内で異なる文脈で使用される用語を特定しました[57]。
さらに、LLMは要件ドキュメントの評価にも利用されており、生成された要件とコードが期待される品質基準を満たしているかを確認します。ChatGPTを使用したユーザーストーリー品質評価では、有望な結果が得られましたが、さらなる最適化と改善が必要です[58]。また、LLMを使用して要件満足度評価を自動的に処理し、設計要素が与えられた要件を完全にカバーしているかどうかを評価する研究も行われていますが、実際のアプリケーションでのさらなる検証と最適化が必要とされています[59]。
B. LLMベースのエージェントのタスク
現在、要件工学におけるLLMベースのエージェントの応用はまだ初期段階にありますが、いくつかの有益な研究があります。LLMベースのエージェントは、要件抽出、分類、生成、および検証のタスクにおいて効率と正確性をもたらします。これらのシステムは、タスクの分割と協力を通じて、従来のLLMよりも高いレベルの自動化と精度を示します。
例えば、半構造化ドキュメント生成におけるマルチエージェントシステムの応用が効果的であることが示されています[60]。このフレームワークでは、セマンティック認識、情報検索、およびコンテンツ生成のタスクを組み合わせ、公共管理分野のドキュメント作成と管理を効率化します。
また、AI支援ソフトウェア開発フレームワーク(AISD)は、要件工学におけるLLMベースのエージェントの自律性を示しています[61]。このフレームワークは、ユーザーフィードバックと対話を通じて生成されたユースケースとコードを継続的に改善および最適化します。実験結果によると、AISDはユースケースの合格率を75.2%に大幅に向上させました。
自動運転の安全要件生成においても、LLMベースのエージェントはマルチモーダル機能を導入することで独自の利点を示しています。このシステムはLLMを自動エージェントとして使用し、検証段階まで最小限の人間の介入で安全要件を生成および改良します[62]。
アジャイルソフトウェア開発においては、ユーザーストーリーの品質が開発サイクルと顧客期待の実現に直接影響します。ALASシステムは、オーストリア郵政グループITの6つのアジャイルチームで成功裏に応用され、自動分析と強化を通じてユーザーストーリーの明確さ、理解しやすさ、およびビジネス目標との一致を大幅に改善しました[63]。
これらの研究は、LLMベースのエージェントが要件工学のタスクにおいて高い自律性と効率性を発揮する可能性を示しています。
C. 分析
LLMベースのエージェントを要件工学に応用することで、効率の向上と品質保証が実現されています。これらのシステムはマルチエージェントの協力と自動処理を通じて、手作業の介入を減らし、要件生成と検証の精度と一貫性を向上させます。LLMベースのエージェントのタスクは、要件生成や記述の補完にとどまらず、要件ドキュメントの生成が自動化プロセスの一部として統合されています。実際の応用では、高度なソフトウェア設計などの多くのタスクが単純なLLMでは達成できません。LLMベースのエージェントは、この問題に対処するためにマルチエージェント協力システムを中心に展開され、要件ドキュメントの欠点を継続的に分析し、改善します。これは将来的に要件工学におけるLLMベースのエージェントの主な応用傾向となるでしょう。
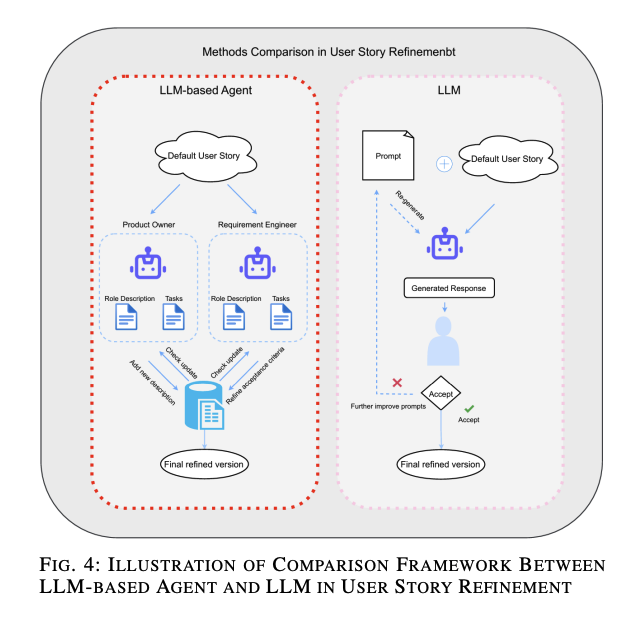
現在、要件工学におけるLLMベースのエージェントの応用はまだ限定的であり、主にマルチエージェントシステムの協力的な利点を活用して要件工学ドキュメントを生成および改良することに焦点を当てています。図4に示すように、[58]および[63]で提示されたアーキテクチャを大まかにシミュレートし、ユーザーストーリーの生成と改良に適用されている2つのアーキテクチャの違いを明確に比較できます。左側はLLMベースのエージェントのアーキテクチャであり、右側はプロンプトエンジニアリングとLLMのみを使用してユーザーストーリーを改良するアプローチです。図は、2つのアプローチの核心的な違いを強調するために、より詳細で複雑な側面を省略しています。LLMベースのエージェントは、共有データベースを利用して異なる専門的な視点から継続的に改善できます。LLMベースのエージェントに関する論文は多くありませんが、LLMからLLMベースのエージェントへの移行の傾向と利点を観察することができます。
要約すると、LLMベースのエージェントは、タスクの分割と協力を通じて、従来のLLMよりも高いレベルの自動化と精度を提供し、要件工学の分野での応用可能性を広げています。
D. ベンチマーク
要件工学は、バグ修正やコード生成のように多数の公開データセットが存在するわけではなく、HumanEvalのような一般的なベンチマークも少ないです。多くの要件工学のモデルのトレーニングデータセットは、著者が自ら収集したものであり、すべてがオープンソース化されているわけではありません。このため、要件工学のデータセットは限られています。例えば、特定のベンチマークデータセットに言及せず、実際の例やケーススタディに焦点を当てて提案されたプロンプトパターンの有効性を示す論文もあります[55]。
データセットの具体例:
- [50]では、平均長、タイプトークン比率(TTR)、および語彙密度(LD)に特徴付けられる4つのデータセットが主に使用されています。これには、PROMISE NFRデータセットからの15プロジェクトにわたる249の非機能要件(NFR)を含むNFRマルチクラス分類データセットや、Google PlayとApple App Storeからの1800のアプリレビューを含むアプリレビューNFRマルチラベル分類データセットなどが含まれます。
- [56]では、合計で23,000以上の文を含む40の要件仕様からなるPUREデータセットを使用し、BERTの要件完成能力をテストしています。
- [64]では、6つの質問に対する36の回答(ChatGPTが生成した6つの回答と5人のRE専門家による30の回答)からなるベンチマークデータセットを使用しています。
これらのデータセットは、モデルの評価指標として機能します。これらの論文を総合すると、要件工学におけるLLMのベンチマークデータセットには、さまざまなソフトウェア要件や機能・非機能要件の分類が含まれ、モデルがこの分野を学習するのに役立っています。データセットの利用は非常に柔軟で多様化しています。
LLMベースのエージェントの研究では、データセットの選択と構築も重要です。例えば、[47]では、公共管理分野からのセマンティックテンプレートで構成されるデータセットを使用しています。これらのテンプレートには、公式証明書や公共サービスフォームなどのさまざまな半構造化ドキュメント形式が含まれています。詳細な構成は明記されていませんが、これらのテンプレートには多くの実践例や文脈情報が含まれており、マルチエージェントシステムが生成するドキュメントが実際のニーズを満たすことを保証しています
要件工学におけるLLMベースのエージェントの研究では、データセットの選択と構築が重要です。公開データセットが少ないため、研究者は自ら収集したデータセットを使用することが多いです。以下は具体的なデータセットの例です:
- CAASDデータセット:AI支援ソフトウェア開発システムの評価用に特別に構築されたベンチマークデータセットで、さまざまなドメインの72のタスクを含みます。各タスクにはシステム要件を定義する参照ユースケースが含まれています[61]。
- Design Science Methodology:[62]では、特定のデータセットは言及されていませんが、実際の適用とケーススタディを通じてモデルの有効性を検証しています。
- ALASシステムの評価:モバイル配送アプリケーションプロジェクトから得られた25の合成ユーザーストーリーを使用し、オーストリア郵政グループITの6つのアジャイルチームでテストしています[63]。
これらの論文からわかるように、要件工学におけるLLMベースのエージェントの研究では、実際のプロジェクトやケーススタディに基づいたデータセットが多く、標準化された大規模データセットが不足しています。研究者は、実践的な応用と反復的な改善を通じてモデルの性能を検証することに重点を置いています。このアプローチは柔軟であり、特定の目的に合わせることができますが、データセットの標準化とスケーリングに関する課題も浮き彫りにしています。今後、より多くの公開データセットが構築され共有されることで、要件工学におけるLLMベースのエージェントの応用がさらに広がり、深まることが期待されます。
E. 評価指標
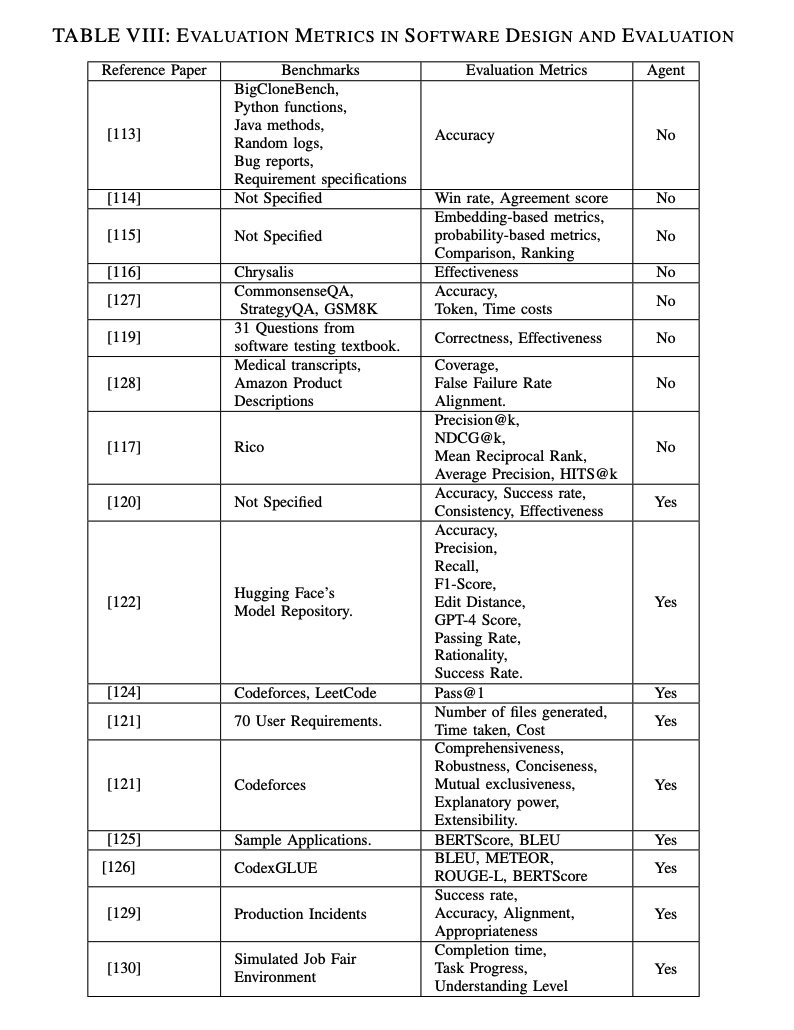
要件工学の分野では、LLMとLLMベースのエージェントはさまざまな指標で評価されます。これには、精度、再現率、F1スコアなどの伝統的な指標に加え、要件工学の特性に合わせた特定の指標が含まれます。これらの評価を通じて、モデルがどのように評価され、要件工学の実践をどのように変えているかがわかります。特定の評価指標は以下の通りです:
- [51]の研究:情報検索の有効性を評価するための精度と再現率に加え、要件仕様の品質指標としての明確さ、一貫性、コンプライアンスが含まれます。この多次元評価方法により、LLMの運用パフォーマンスだけでなく、要件仕様の品質を維持する能力も測定されます。
- [52]の研究:生成された仕様の品質を測定するためにリッカート尺度を使用し、曖昧さ、理解しやすさ、簡潔さなどの観点から評価します。この尺度は1から5の合意度でスコアリングされます。
- [63]の研究:エージェントの自律性と交渉力を評価し、エージェントがユーザーと対話し、特定のプロジェクトニーズに適応する能力を測定します。これにより、LLMベースのエージェントが要件管理と意思決定の最適化においてどのように価値を提供するかが明らかになります。
表Vに示されているように、要件工学におけるLLMの評価にはF1スコアなどの一般的な指標が必要です。しかし、LLMベースのエージェントでは、要件ドキュメント生成のパフォーマンスから最終製品の品質への評価がシフトします。評価指標は、合格率やフィードバックなどのユーザー満足度に重点を置きます。要するに、LLMベースのエージェントは高レベルな開発を達成するためにLLM自体を活用し、そのタスクの性質に大きく依存しています。
結論として、エージェントモデルの特性は、複雑な意思決定と学習能力を反映し、人間や他のツールと協力することで高いスケーラビリティと柔軟性を提供する潜在的な利点を示しています。この現象は、将来のソフトウェア開発において、LLMベースのエージェントを使用することで、要件抽出と処理の方法がより効率的で正確になり、ステークホルダーのニーズにより適合するように継続的に改善される可能性を示唆しています。
V. コード生成とソフトウェア開発
コード生成とソフトウェア開発は、ソフトウェア工学の中核的な領域であり、開発プロセスにおいて重要な役割を果たします。LLMをコード生成に使用する主な目的は、自動化プロセスを通じて開発効率とコード品質を向上させ、開発者とユーザーのニーズを満たすことです。近年、コード生成とソフトウェア開発におけるLLMの応用は大きな進展を遂げ、開発者の作業方法を変え、自動化開発プロセスにおける変化を示しています。
要件工学と比較して、コード生成とソフトウェア開発におけるLLMおよびLLMベースのエージェントの応用研究は、より広範かつ深いものです。自然言語処理と生成技術を使用して、LLMは複雑なコードスニペットを理解し生成し、コードの記述やデバッグからソフトウェアの最適化までのさまざまな段階を自動化することで、開発者を支援します。GPT-4などのデコーダーベースの大規模言語モデルは、正確なコード提案と自動デバッグを提供することで、開発効率を大幅に向上させる可能性を示しています。
最近では、LLMベースのエージェントのソフトウェア開発への応用も注目されています。これらの知能エージェントは、複雑なコード生成タスクを実行するだけでなく、自律的な学習と継続的な改良を行い、動的な開発環境で柔軟な支援を提供します。GitHub Copilot[12]のようなツールは、LLMを統合することで、プログラミング効率とコード品質の向上においてその利点をすでに実証しています。
コード生成とソフトウェア開発におけるLLMの具体的な利点と応用例を以下に示します:
- コード生成:自然言語での記述を元に、正確なコードを自動生成します。
- デバッグ:自動デバッグ機能により、バグの早期発見と修正が可能です。
- コード最適化:既存のコードを分析し、最適化の提案を行います。
- 学習と改良:LLMベースのエージェントは、ユーザーからのフィードバックを元に学習し、継続的に改善されます。
LLMとLLMベースのエージェントは、ソフトウェア開発プロセスを効率化し、開発者の生産性を向上させる強力なツールとなっています。これらの技術は、今後もさらなる進化と応用が期待されます。
A. LLMs Tasks
大規模言語モデル(LLMs)は、コード生成およびソフトウェア開発において自動化と推論を通じてさまざまなタスクを最適化しており、これにはコード生成、デバッグ、コード理解、コード補完、コード変換、およびマルチターンインタラクティブコード生成などが含まれます。主な手法は、自然言語の説明から実行可能なコードを生成することで、モデルは以前に学習したコードスニペットやfew-shot learningを活用してユーザーの要求をよりよく理解します。
1. コード生成とデバッグ
- OpenAIのCodexモデル:
- 使用例: Visual Studio CodeやJetBrainsのIDEに統合。
- パフォーマンス: CodexはGitHubの公開コードで微調整され、Python関数をdoc-stringsから生成する能力を持ち、HumanEvalベンチマークで他の類似モデルを上回る性能を示しました[67]。
- GPT-4の性能評価:
- テキスト-データベース管理およびクエリ最適化:
2. マルチリンガルコード生成
3. プロンプト設計の重要性とコード品質
- プロンプトの質:
- プロンプトがあまりに曖昧または一般的である場合、LLMsはユーザーの真の要求を理解するのに苦労し、一回の試行で望むコードを生成するのが困難です[71]。
4. デバッグ技術
- "print debugging"技術:
- 使用モデル: GPT-4。
- パフォーマンス: 変数の値や実行フローをトラッキングし、Leetcodeでの中程度の難易度の問題で1.5%の向上、より難易度の高い問題では17.9%の向上[71]。
5. プログラミング効率の向上
- GitHub Copilot:
- 使用例: OpenAIのCodexモデルと統合し、リアルタイムのコード補完と提案を提供。
- パフォーマンス: HTTPサーバータスクを55.8%速く完了する結果を示しました[72]。
6. 多ターンプログラム生成
- CODEGENモデル:
- タスク: マルチターンインタラクションを通じてプログラムを生成し、プログラム合成の質を向上。
- パフォーマンス: pass@kメトリクスでCodexモデルを上回る性能を示しました[74]。
7. 自己改善フレームワーク
- Cycleフレームワーク:
- 特徴: 実行フィードバックから学ぶことで、コード生成パフォーマンスを63.5%向上。
- 限界: 決定とプランニング能力はコード生成および改良タスクに限定され、全体的なプランニングは行わないため、進化したLLMアプリケーションとして分類されます[75]。
B. LLMベースのエージェントのタスク
LLMベースのエージェントは、マルチエージェントの協力により、タスク効率と効果を大幅に向上させる潜在力と利点を示しています。従来のLLMとは異なり、LLMベースのエージェントはタスクを複数のサブタスクに分割し、専門のエージェントがそれぞれを処理します。この方法は、タスクの効率を高め、生成されるコードの品質と精度を向上させ、単一のLLMから生じる幻覚を軽減します。
例えば、研究[76]では、複数のChatGPT(GPT-3.5-turbo)エージェントが異なる役割を果たし、複雑なコード生成タスクを共同で処理する自己協力フレームワークを提案しています。特に、ソフトウェア開発手法(SDM)を導入して開発プロセスを分析、コーディング、テストの3つの段階に分けています。各段階は特定の役割が管理し、タスク完了後にフィードバックを提供し、他の役割と協力して生成されたコードの品質を向上させます。この自己協力フレームワークは、HumanEvalとMBPPベンチマークで性能を大幅に向上させました。特にHumanEvalでは、SOTAモデルのGPT-4と比較して最大29.9%の改善を示しています。この結果は、複雑なコード生成タスクにおける協力チームの潜在力を示しています。
同様に、研究[77]では、LCGフレームワークがマルチエージェントの協力とチェインオブソート技術を通じてコード生成の品質を向上させており、ソフトウェア開発プロセスにおけるマルチエージェント協力の有効性を再び示しています。
一方、2024年にケンブリッジ大学のチームが発表した研究[78]では、L2MACフレームワークを導入し、マルチエージェントシステムを通じてメモリと実行コンテキストを動的に管理し、大規模なコードベースの生成においてSOTAの性能を達成しています。このフレームワークは、プロセッサ、命令レジストリ、ファイルストレージ、および制御ユニットの主要コンポーネントに分かれています。実験結果は、HumanEvalベンチマークでPass@1スコア90.2%を達成し、大規模なコードベース生成における優れた性能を示しています。
さらに、MetaGPTフレームワーク[79]や、プロジェクト計画、要件工学、ソフトウェア設計、デバッグなどのタスクを自動化するマルチGPTエージェントフレームワーク[80]、大規模で複雑なソフトウェアプロジェクトの自動コード生成を目的としたCodePoriモデル[81]、およびプログラマエージェント、テストデザインエージェント、テスト実行エージェントと協力してコードを生成および最適化するAgentCoderフレームワーク[82]などが紹介されています。
LLMベースのエージェントの目的は、多くのフレームワークにおいて自己フィードバックと反省能力を強化することです。現在のオープンソースLLMはこの面での能力が低いため、LLMベースのエージェントの登場が、オープンソースモデルとGPT-4のようなプロプライエタリシステムの高度な能力のギャップを埋めることが期待されます。研究[83]では、CodeLlamaとDeepSeekCoderに基づくOpenCodeInterpreterフレームワークを導入し、コード生成、実行、人間のフィードバックを統合することでコード生成モデルの精度を向上させています。また、外部ツールやAPIの使用は、LLMベースのエージェントのもう一つの大きな利点であり、Toolformerモデル[84]やToolLLMフレームワーク[85]は、自己監視を通じてAPIを呼び出す能力を学習し、タスクの性能を大幅に向上させています。
C. 分析
ソフトウェア開発におけるLLMベースのエージェントと従来のLLMの主な違いは、効率性と自律性にあります。従来のLLMは単一モデルで特定のタスク(例えば、テキストからのコード生成やコード補完)を処理しますが、複雑なタスクに対しては限界があります。特に、コンテキストウィンドウの制限や継続的なフィードバックの必要性が課題です。
一方、LLMベースのエージェントは、タスクを明確に分担し協力することで、効率と品質を向上させます。例えば、コード生成タスクでは、あるエージェントが初期コードを生成し、別のエージェントがテストケースを設計し、さらに別のエージェントがテストを実行しフィードバックを提供します。これにより、反復的な最適化が実現されます。
タスクの分割、マルチエージェントシステム、およびツールの統合を通じて、LLMベースのエージェントはより複雑で広範なタスクに対応でき、コード生成の品質と効率を向上させます。このアプローチは、従来のLLMの限界を克服し、将来のソフトウェア開発研究と応用に新しい方向性とアイデアを提供します。これにより、プログラマーは退屈なテストスイートの生成から解放されます。
このように、LLMベースのエージェントは、従来のLLMに比べて優れた効率性と自律性を持ち、より複雑なタスクに対応できるため、ソフトウェア開発において非常に有用です。
ソフトウェア工学におけるタスク処理では、LLMとLLMベースのエージェントにはタスクの焦点、アプローチ、複雑さとスケーラビリティ、自動化レベル、タスク管理において微妙な違いがあります。
- LLM:主に単一のLLMによるコード生成能力の向上に焦点を当てています。デバッグ、精度、評価などの特定の側面を改善する方法が一般的であり、コンテキストウィンドウや単一タスク実行などの既存の制約内でのパフォーマンス向上に集中しています。
- LLMベースのエージェント:複数の専門化されたLLMやフレームワークの協力を通じて、より複雑で広範なタスクを処理します。ツールの使用、反復テスト、マルチエージェントの調整を統合して、開発プロセス全体を最適化します。これにより、一般的なベンチマークでの最先端モデルを容易に上回ることができます。
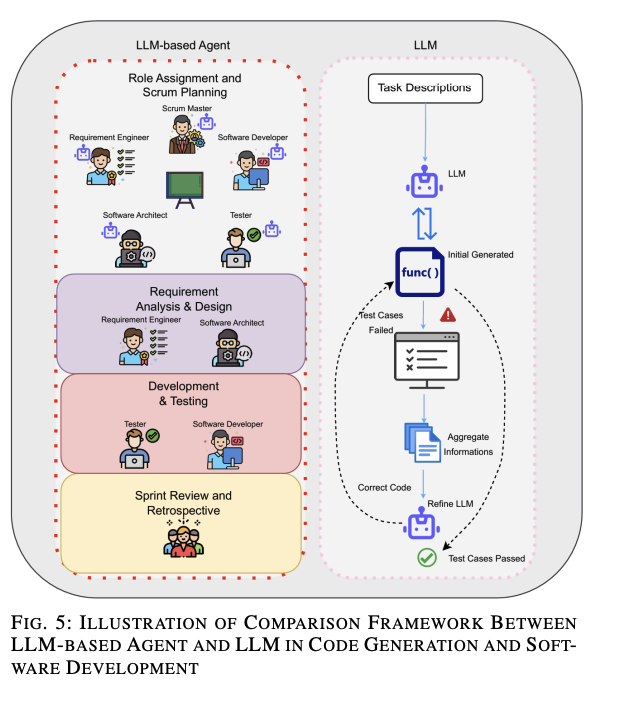
図5の例
図5は、[77]と[75]の研究を利用して、同じコード生成タスクにおけるLLMベースのエージェントとLLMの違いを示しています。
- LLMベースのエージェントシステム:マルチエージェントの協力を実行し、業界での実際のスクラム開発チームを模倣できます。
- LLM:通常、マルチLLMを使用してテストケースからのミスを分析し、初期生成コードを改良しますが、自律性と効率性に欠け、テストケースは人間が手動で生成します。
これらの違いにより、LLMベースのエージェントはタスクの複雑さとスケーラビリティに対する優れた効率性と自律性を持ち、より複雑なタスクに対応できるため、ソフトウェア開発において非常に有用です。
D. ベンチマーク
コード生成とソフトウェア開発の分野では、LLMとLLMベースのエージェントの研究に使用されるデータセットには顕著な違いと共通点があります。これらのデータセットは、モデルのパフォーマンスを評価するための重要なベンチマークを提供します。
共通のデータセット
- HumanEval: OpenAIによって手作業で作成された164のプログラミング問題を含み、自然言語の記述を実行可能なコードに変換するモデルの能力を評価します[76]。
- MBPP (Mostly Basic Python Programming): 427のPythonプログラミング問題を含み、さまざまなプログラミングシナリオでモデルの性能を評価します[82]。
- HumanEval-ETとMBPP-ET: HumanEvalとMBPPの拡張版で、より多くのテストケースと複雑な問題を追加してモデルの性能を総合的に評価します[86]。
- SpiderとBIRD: 自然言語からSQLクエリへの変換を評価するデータセットで、複雑なクエリ生成タスクを扱います。
- ToolBenchとAPIBench: ツールやAPIの使用能力を評価するためのデータセットで、ToolBenchには16,464の実際のRESTful API指示が含まれています[85]。
特定のデータセット
- CAASD (Capability Assessment of Automatic Software Development): さまざまなドメインの72のソフトウェア開発タスクを含み、AI支援ソフトウェア開発システムを評価するために使用されます[61]。
共通点と違い
- 共通点: HumanEvalやMBPPなどのデータセットは、幅広いプログラミングタスクと言語をカバーしており、コード生成能力を評価するために広く使用されています。また、多言語およびクロスドメインのデータセット(HumanEval-XやCodeSearchNetなど)も多く採用されています。
- 違い: LLMベースのエージェントは、マルチエージェントの協力フレームワークを使用して複雑なタスクを処理するため、マルチターンインタラクションや反復最適化を重視するベンチマークデータセットを好みます。例えば、TOOLLLMはToolBenchとAPIBenchを使用してツール使用能力を評価し、Toolformerはツールの自律的な学習能力を示しました。
これらの違いは、LLMとLLMベースのエージェントのタスク処理アプローチの違いに起因しています。LLMは通常、関連するデータセットでファインチューニングすることで単一モデルの性能を最適化しますが、LLMベースのエージェントは複数のエージェントの協力とツールの統合を通じてより複雑なタスクを処理します。
E. 評価指標
コード生成とソフトウェア開発におけるLLMとLLMベースのエージェントのパフォーマンスを評価するために、さまざまな評価指標が使用されます。これらの指標は、特定のタスクにおけるモデルの性能と、コード生成およびソフトウェア開発プロセスの改善度を測定します。
共通の評価指標
- Pass@k: 初回からk回目までに生成されたコードがすべてのテストケースに合格する割合を測定します。これは、さまざまなデータセットで広く適用されています[86]。
- BLEUスコア: 生成されたコードと参照コードの構文的類似性と正確性を測定します[73]。
- 完了時間と成功率: AI支援開発ツールの生産性への影響を評価するために重要です。正確なコードを生成しながら期待される速度を維持することが求められます。
- Confidence CalibrationとExecution Rate: ユーザーの意図を理解し、高精度で正しいコードを生成するモデルの信頼度と実行成功率を評価します。
LLMベースのエージェントの評価指標
- Pass@k: 単一モデルの評価にも使用されますが、マルチエージェント協力特性を反映するためにさらに多様です。
- Win RateとAgreement Rate: マルチエージェントの協力効果を評価するために重要です。
- Execution EffectivenessとCost Efficiency: 実世界のアプリケーションでの性能を評価します。MetaGPT[79]では、コード生成の正確性だけでなく、実行効果、開発コスト、生産性も分析されています。
総合的な評価指標
LLMベースのエージェントは、複数のエージェントと開発プロセス全体のパフォーマンスを評価するために、より包括的で多様な指標が必要です。これには、人的修正コストや質的フィードバックが含まれます。エージェントアプリケーションが広範なプロジェクトに関与することが多いため、ユーザーや開発者の満足度指標も考慮されます。これらの指標は、コード生成の正確性だけでなく、エージェントシステムのリソース利用効率にも焦点を当てています。
VI. 自律学習と意思決定
自律学習と意思決定は、現代のソフトウェア工学において重要かつ進化し続ける分野です。特に人工知能とビッグデータの影響下で、自律学習と意思決定の核心的なタスクは、機械学習アルゴリズムと知能システムを通じてデータ分析、モデル構築、意思決定の最適化を自動化することです。これにより、システムの自律性と知能が向上します。
LLMとLLMベースのエージェントの役割
自律学習におけるLLM
- 複雑な言語タスクの処理: LLMは複雑な言語タスクを処理し、強力な推論と意思決定能力を示します。
- 自動デバッグと自己修正: LLMは効率的なエラー識別と修正を通じて、自律学習能力を向上させます。
- 投票推論: 複数のLLMコールを使用した投票推論(例えば、多数決法[89])が、推論システムの精度を向上させ、最適な可能性を選択します。
自律学習におけるLLMベースのエージェント
- 複雑な推論と意思決定タスク: LLMベースのエージェントは、LLMの助けを借りて複雑な推論と意思決定タスクを実行します。
- 継続的な学習と最適化: これらのエージェントは、動的な環境での適応性を向上させるために、継続的な学習と最適化を行います。
調査の概要
- 研究数: この分野でのLLMベースのエージェントに関する研究論文を19本収集しました。
- 調査内容: これらの研究の一般的なレビューを提供し、自律学習と意思決定における具体的な応用と技術的実装を分析します。
この調査は、自律学習と意思決定におけるLLMとLLMベースのエージェントの応用可能性と技術的アプローチを理解するための全体的なレビューを提供します。
A. LLMのタスク
API呼び出し
- LLMのAPI呼び出しは、継続的な呼び出しが必要とされますが、呼び出し回数の増加が必ずしもパフォーマンスを向上させるわけではありません。研究[90]では、LLM呼び出しの増加とシステム性能の関係が非線形であることが示されています。パフォーマンスは初期に改善されますが、一定の閾値を超えると低下します。
自動デバッグ
- SELF-DEBUGGINGメソッド[91]:LLMが実行結果と自然言語の説明を分析してコードをデバッグします。実験結果は、モデルの正確性を2-12%向上させることを示しています。
- AutoSD (Automated Scientific Debugging)[92]:科学的デバッグプロセスをシミュレートし、説明可能なパッチコードを生成します。このメソッドはデバッグ結果に基づいて最適な修正ソリューションを自動的に決定し、具体的なコード実装を提供します。
創造性と意思決定
- 創造性理論の分析[93]:LLMの出力を価値、新規性、驚きなどのメトリクスで評価し、現在のLLMには組み合わせ的、探索的、変革的な創造性の限界があることを示しています。
- 意思決定の実験[94][95]:LLMを裁判官として使用し、他のLLM駆動のチャットアシスタントを評価させる研究。GPT-4の判断は人間の判断と高い一致率を示しています。
これらの研究は、LLMが複雑なタスクにおける自律学習と意思決定能力を持ち、その性能を最適化するための新しい方法を提供することを示しています。
B. LLMベースのエージェントのタスク
マルチエージェント協力と対話フレームワーク
- CMDフレームワーク: 研究[96]では、マルチエージェントディスカッションがLLMの推論能力を強化するかどうかを調査。結果は、マルチエージェントディスカッションが常識知識と数学的推論タスクのパフォーマンスを向上させることを示し、単一エージェントの判断ミスや誤答の伝播を修正します。
- PCA-EVALベンチマーク: 研究[97]では、GPT4-VisionのようなマルチモーダルLLMがエージェントの自律的意思決定プロセスを強化する潜在力を探求。結果は、自律運転、ホームアシスタント、ゲーム分野での優れたパフォーマンスを示しました。
自己反映と言語フィードバック
- Reflexionフレームワーク: 研究[98]では、従来の重み更新を避けるために自己反映と言語フィードバックを使用。HumanEval Pythonプログラミングタスクでの成功率が80.1%から91.0%に向上し、ALFWorld意思決定タスクでの成功率が22%向上、HotPotQA推論タスクでのパフォーマンスが14%向上。
- ExpeLエージェントフレームワーク: 研究[35]では、自然言語を使用して経験を収集し、知識を抽出。内部データベースへのアクセスにより幻覚を減少させ、RAG技術を活用して意思決定能力を向上。実験結果は、ExpeLが複数のドメインでのタスクにわたり連続的に改善し、タスク間の転移学習能力を示しました。
これらの研究は、LLMベースのエージェントが自己フィードバック、自己反映、経験の蓄積を通じて自律学習と意思決定プロセスを最適化し、動的かつ複雑なタスクに対する高い自律性と柔軟性を示すことを示しています。従来のLLMとは異なり、LLMベースのエージェントはリアルタイムでの継続的な自己学習とフィードバックメカニズムを通じてパフォーマンスを向上させ、さまざまなタスクで優れたパフォーマンスを発揮します。
AGENTVERSEフレームワーク
- AGENTVERSE: 研究[99]では、協力を通じてタスク完了の効率と効果を向上させるために設計されたマルチエージェントフレームワークを提案。エキスパートエージェントの協力システムを設計し、テキスト理解、推論、コーディング、ツール使用のタスクで優れたパフォーマンスを発揮します。実験では、グループ協力により独立したタスク完了だけでなく、パフォーマンスが大幅に向上しました。
CAMELフレームワーク
- CAMEL: 研究[100]では、スケーラブルな技術を構築し、自律的な協力エージェントフレームワークを支援するためのフレームワークを提案。エージェントの行動と能力を研究するために対話データを生成し、LLaMA-7Bモデルの微調整によってエージェント性能を強化しました。
BOLAAフレームワーク
- BOLAA: 研究[101]では、複雑なタスクを効率的に解決するための新しいマルチエージェント協調戦略を提案。WebShop環境で他のエージェントアーキテクチャよりも優れた性能を発揮しました。
エージェント数の増加とパフォーマンス向上
- 研究[44]では、エージェント数の増加がLLMの性能向上に寄与することを示しています。サンプリングと投票法を使用し、算術推論、一般推論、コード生成タスクでのLLMの性能が大幅に向上しました。
これらの研究は、マルチエージェント協力と対話フレームワークが自律学習と意思決定タスクにおいて重要であることを示しています。従来のLLMと比較して、これらのマルチエージェントフレームワークはゼロショット学習における推論の正確性を向上させ、高い自律性と柔軟性を示し、開発者の負担を軽減します。
自己進化と信頼行動のシミュレーション
- SELFフレームワーク: 研究[102]では、自己フィードバックと自己改善を通じてLLMの能力を向上させるためのSELFフレームワークを提案。実験では、GSM8KとSVAMPデータセットでテスト精度がそれぞれ6.82%と4.9%向上。
- 信頼行動のシミュレーション: 研究[103]では、LLMベースのエージェントが人間の信頼行動をシミュレートできるかどうかを検討。信頼ゲームのバリエーションを通じて、GPT-4が人間の期待に一致する信頼行動を示すことが確認されました。
タスク処理の複雑性
- AgentLite: 研究[104]では、タスク指向のLLMベースのエージェントシステムの開発、プロトタイピング、および評価を簡素化する軽量でユーザーフレンドリーなライブラリを提案。
- GPTSwarm: 研究[105]では、LLMベースのエージェントを計算グラフとして表現し、プロンプトエンジニアリング技術を統一するフレームワークを提案。GAIAベンチマークで最大90.2%の性能向上を実証。
これらの研究は、LLMベースのエージェントが複雑なデータ分析タスクを実行し、人間の信頼行動をシミュレートする潜在力を持つことを示しています。また、エージェントの自己進化と柔軟なタスク処理能力は、将来の人間-機械協力と人間行動シミュレーションのための重要な理論的基盤を提供します。
C. 分析
全体として、LLMとLLMベースのエージェントは、自律学習と意思決定において強力な能力を示していますが、タスクの実行焦点や自律性、インタラクティブ性、学習および適応メカニズム、他のシステムやモダリティとの統合においてわずかな違いがあります。
タスク実行の焦点
- LLMs:
- LLMベースのエージェント:
- 複数のタスクを同時に管理し、動的な意思決定と他のエージェントやシステムとの相互作用を含む。
- マルチエージェントディスカッションを通じた推論の強化、経験からの継続的な学習、リアルタイムの動的意思決定、視覚環境でのマルチモーダルタスクに対応。
自律性とインタラクティブ性
- LLMs:
- 外部入力や環境変化に適応する必要がない、高度に特定されたタスクを実行するように設計。
- 主にテキスト入力出力シナリオで動作し、テキストベースのコンテンツを処理および生成。
- LLMベースのエージェント:
- 環境にリアルタイムで適応し、相互作用する高い自律性を示す。
- マルチエージェントシステムの一部として、協力とコミュニケーションが重要な要素。
- 他のシステムやモダリティ(視覚入力や実世界の知覚データなど)と統合し、より複雑でコンテキストベースの意思決定タスクを実行。
結論
LLMベースのエージェントは、LLMよりも高い自律性と柔軟性を示し、複雑なタスクに対応する能力が向上しています。これにより、動的で複雑な状況での意思決定プロセスを最適化し、将来の人間-機械協力の基盤となります。
学習と適応メカニズム
- LLMs:
- 学習と適応は主にモデルのトレーニングデータとパラメータ範囲に制限されます。
- 新しいデータ更新を通じて適応できますが、リアルタイムフィードバックから継続的に学習する能力は欠けています。
- 既存の知識を使用して問題を解決し、応答を生成することに重点を置いています。
- LLMベースのエージェント:
図6: Expelフレームワーク
Expelフレームワークは、以下の要素を統合しています:
- ReAct: 実行と反応のフレームワークで、エージェントが実行と反応のサイクルを通じて学習する方法を提供します。
- Reflexion: 言語フィードバックを利用して自己改善を行い、リアルタイムの自己反省メカニズムを強化します。
このフレームワークは、過去の知識から学び、連続する意思決定を支援する自律的意思決定能力を示します。これは従来のLLMフレームワークが達成できないものであり、LLMベースのエージェントの優れた自律学習と適応メカニズムを示しています。
結論
LLMとLLMベースのエージェントの主な違いは、特定タスクへの焦点とそれに伴う学習と適応のメカニズムにあります。LLMは既存の知識を活用して問題を解決することに特化している一方で、LLMベースのエージェントは、リアルタイムのフィードバックを通じて継続的に学習し、より高い自律性と適応性を持ち、複雑で動的なタスクに対応する能力を向上させています。
D. ベンチマーク
自律学習と意思決定の分野において、LLMs(大規模言語モデル)およびLLMベースのエージェントが使用するベンチマークデータセットは、タスク処理およびアプリケーション要件において非常に類似しています。異なるタスクやアプリケーションコンテキストでの両アプローチの強みと弱みをより深く理解することができます。具体的なデータセットの参照については、表 VII を参照してください。
LLMsの研究では、主なデータセットにDefects4J、MMLU、TransCoder、およびMBPPが含まれます。これらのデータセットは主に特定のドメインやタスクにおけるモデルの性能を評価するために使用されます。Defects4Jはソフトウェア工学で広く使用されており、17のJavaプロジェクトから525の実際の欠陥を含むソフトウェア欠陥データセットです。これは、異なる手法の性能を比較できる標準化されたベンチマークを提供することで、プログラムの自動修正や欠陥検出ツールの効果的なテストに役立ちます。MMLU(Massive Multitask Language Understanding)は、57の科目をカバーする大規模ベンチマークデータセットで、モデルの知識と推論能力を広範囲にわたってテストします。これは小学校教育から大学の数学、ビジネス倫理、大学の化学のような専門レベルの質問を含み、モデルの多様な知識ベースおよび推論能力を試します。TransCoderデータセットはプログラム言語間のコード翻訳に焦点を当てており、モデルがあるプログラム言語から別のプログラム言語へ自動的にコードを翻訳する能力を評価します。これは多言語でのソフトウェア開発と保守にとって非常に重要であり、開発効率を大いに向上させることができます。MBPP(Mostly Basic Python Programming)は前のセクションで導入済みですが、基本的な概念と標準ライブラリ関数をカバーする427のPythonプログラミング問題を含むデータセットで、異なるプログラミングシナリオにおけるモデルの性能をテストするために広く使用されます。
一方、LLMベースのエージェントは、複雑なシナリオでのマルチタスクと意思決定能力に重点を置いたデータセットを使用します。主なデータセットには、HotpotQA、ALFWorld、FEVER、WebShop、およびMGSMが含まれます。HotpotQAはマルチホップ質問応答データセットであり、モデルが質問に答える際に複数のドキュメントからの内容を参照する必要があり、情報合成および推論能力を評価します。このデータセットはモデルの複雑な推論タスクでの性能を試します。ALFWorldはテキストベースの環境シミュレーションデータセットであり、仮想家庭環境でタスクを完了するためのマルチステップ意思決定を必要とします。データセットは自然言語処理と意思決定を組み合わせ、動的かつインタラクティブなタスクにおけるモデルの性能を評価します。FEVER(Fact Extraction and VERification)データセットは事実検証タスクに使用され、モデルが与えられた発言の真偽を検証し、証拠を提供する必要があり、情報検索および論理推論の能力を評価します。WebShopは1.18百万の実際の製品と人間の指示を含むオンラインショッピング環境シミュレーションデータセットであり、ショッピングタスクの完了や属性マッチングのような複雑な意思決定タスクでのモデルの性能をテストするために使用されます。MGSM(Multimodal Generalized Sequence Modeling)は対話、創造的な文章作成、数学的推論および論理推論に関連するタスクを含むマルチモーダルデータセットであり、マルチモーダルタスクにおけるモデルの総合的な能力を評価します。
比較してみると、LLMデータセットは通常、コード生成、数学的推論、創造的な文章作成のような単一かつ静的なタスクに焦点を当てており、事前に定義されたタスク範囲内で作業するモデルに適しています。Defects4J、MMLU、およびMBPPのようなデータセットは特定のドメインにおけるモデルの能力を評価するのに役立ちます。LLMベースのエージェントは、マルチモーダル入力およびリアルタイム意思決定を必要とする複雑でマルチタスクかつ動的な環境に適しており、複雑なインタラクションおよびマルチタスクシナリオを処理するにあたっての優位性を示すことができます。HotpotQA、ALFWorld、FEVER、およびWebShopのようなデータセットは、情報合成、動的意思決定/インタラクション、およびマルチモーダルタスクにおけるモデルの性能を試します。この違いは、両者の設計目標の違いから生じます:LLMsは単一タスクの性能を最適化することを目的とし、LLMベースのエージェントは複雑またはマルチモーダルタスクを処理するように設計されており、より高い自律性と適応性を必要とします。これは、現代のアプリケーションが高度にインタラクティブで適応性が高く多機能なAIシステムを求めており、単一のLLMモデルからマルチエージェントシステムへの開発の推進を反映しています。これらの分析を通じて、自律学習および意思決定におけるLLMsおよびLLMベースのエージェントの異なるアプリケーションを特定することができ、現実のアプリケーションにおいて異なるタスク要件を満たすために適切なフレームワークを選択することが重要です。
E. 評価指標
LLMs(大規模言語モデル)およびLLMベースのエージェントの研究では、さまざまな評価指標が使用されており、これらの指標は特定のタスクにおけるモデルの性能を評価し、この分野での応用効果を分析するために使用されます。以下では、評価指標を分析したいくつかの代表的な研究を検討し、LLMsとLLMベースのエージェントの違いを探ります。
LLMsの研究では、評価指標は主にモデルの精度とタスク完了に焦点を当てています。例えば、[90] の研究では、投票推論システムの精度が0/1の損失(正解の回答の割合)で測定され、モデルの性能を評価しました。この指標は、複数回の呼び出しを通じてモデルの精度を評価し、反復的推論を通じてLLMsが結果の精度を向上させる能力を反映します。文献で一般的な評価指標には、精度とサンプル効率があり、精度はモデルが行う正解の予測の割合を示し、サンプル効率は特定の精度レベルを達成するために必要なサンプルの数を測定します。これらの指標は、モデルの予測および意思決定能力とトレーニング中のデータ利用効率の両方を評価します。[92] の研究では、可能なパッチ、正しいパッチ、精度、および開発者の精度が評価指標として含まれます。可能なパッチとはすべてのテストに合格するパッチのことを指し、正しいパッチは元の開発者のパッチと意味論的に同等であるものを指します。精度は可能なパッチの中の正しいパッチの割合を測定し、開発者の精度は説明の有無にかかわらずパッチの正確性を人間の評価を通じて評価します。これらの指標はモデルの説明能力と自動コード修正の実用的な有効性を強調し、人間の評価に対する依存度を高めます。
モデルの創造性を評価するために、価値、新規性、および驚きが創造性の次元として使用されます。生成された作品の質、社会的受容性、および類似性と、クリエイティブな製品を生成する能力も評価に含まれます。[110] の研究では、24ゲームの成功率と創造的な文章作成で生成された段落の一貫性を評価指標として使用しました。これらの指標は、問題解決およびテキスト生成におけるモデルの性能を評価し、LLMsの複雑な問題の解決と一貫したテキストの生成の可能性を示します。[95] の研究では、一貫性と成功率が評価指標として使用され、一貫性はランダムに選ばれた質問に対する2人の判事の合意の確率を計算し、LLM判事が人間の好みと一致する度合いを測定します。成功率は特定のタスク(例えば24ゲーム)の正解回答率を測定するために使用されます。
一方、LLMベースのエージェントは、マルチエージェントの協力特性を反映するために、より多様な評価指標を使用します。[97] の研究では、評価指標には感知スコア(P-Score)、認知スコア(C-Score)、および動作スコア(AScore)が含まれます。これらの指標は、モデルの感知、認知、および動作能力を包括的に評価し、マルチモーダルタスクを処理するLLMベースのエージェントの総合的なパフォーマンスを示します。マルチモーダル応用においては、成功率(SR)が主要な指標としてしばしば使用され、HotpotQAやFEVERなどのタスクを通じて正確なマッチングの成功を評価します。これらの指標は、タスク完了の成功と精度に焦点を当て、異なるタスク環境でのLLMベースのエージェントの実用的な実行能力を示します。[111] の研究では、評価指標には実務者のフィードバック、効率、および精度が含まれます。実務者のフィードバックは、リッカートスケールを使用して満足度およびパフォーマンスのフィードバックを収集します。リッカートスケールは、特定の発言に対する個人の態度や意見を測定するための一般的に使用される心理測定ツールであり、通常次の5つの選択肢を含みます:非常に同意しない、同意しない、中立、同意する、非常に同意する。効率と精度は実務者によって検証されたモデル実行の質的データ分析の有効性を通じて測定されます。これらの指標は、質的なデータ分析におけるエージェントのパフォーマンスを評価し、実用性と実際の応用における正確性を示します。
これらの指標を比較することによって、LLMsは従来の指標(例:精度、サンプル効率)を使用してその能力を評価することが判明しました。一方、LLMベースのエージェントは、マルチエージェントを用いたより複雑なアルゴリズムを処理し、多方向からそのパフォーマンスを評価するために、より包括的で多様な指標を必要とします。マルチモーダルタスクおよび自己進化タスクにおけるLLMベースのエージェントは、感知、認知、および動作能力の統合されたパフォーマンスを強調します。この違いは、シングルタスクの最適化におけるLLMsの強みと、より高い自律学習能力を持つ複雑なタスクの協調処理におけるLLMベースのエージェントの可能性を反映しています。さらに、実務者のフィードバック、効率、精度などのLLMベースのエージェントの実用的な評価指標は、現実のシナリオにおける有用性およびユーザー満足度を示します。この評価アプローチは、タスクの完了を評価するだけでなく、ユーザーエクスペリエンスの包括的な評価も考慮に入れ、その意思決定能力の人間との一致度も評価できます。
VII. ソフトウェア設計と評価
LLMs(大規模言語モデル)のソフトウェア設計と評価への応用は、前述のトピックと非常に似た重なりを持っています。ソフトウェア設計はソフトウェア開発の初期段階であり、その品質が将来の開発の品質に直接影響を与えます。現代のソフトウェア工学の方法論は、設計段階での意思決定がシームレスに高品質なコードに変換されるように、設計と開発の統合を強調しています。そのため、ソフトウェア設計に関する研究は、LLMsを利用した特定のフレームワークや特殊なアーキテクチャ設計を介して、コード生成や開発に関する側面を探求することがしばしばあります。
ソフトウェア設計フレームワークはしばしば最適な結果を達成するために、複数の段階で継続的なリファインメントを含むことがあり、これがソフトウェア開発におけるLLM応用の一部と見なされることがあります[83]。同様に、[85]および[84]は、LLMsを使用して開発と設計を支援するツールやAPIインターフェースの頻繁な使用を強調しており、コード生成およびソフトウェア開発のトピックと重なることを示しています。
ソフトウェア設計と評価におけるLLMsは、自律学習と意思決定とも広範に交差しており、これらの2つのトピックは相互に関連した分野です。ソフトウェア設計は、動的な環境に対処するためのシステムの適応性と学習能力を考慮する必要があるため、自律学習と意思決定を含む設計評価がこれら2つのトピックの交差点の焦点となります。多くのLLM技術と方法は、両方の分野で類似の応用を見出しています。例えば、強化学習に基づくLLMsは、自動化された設計決定や評価、自己学習および最適化に使用できます。
ソフトウェア工学におけるLLMsの共通の応用には、パフォーマンスを継続的に向上させるためのプロンプトエンジニアリング技術を使用したモデルのファインチューニングが含まれ、特にソフトウェア設計と評価においては、モデルの出力がユーザーの期待に合致するようにするために、多くのサンプル学習がしばしば必要です[93][102][44][111][105][96]。さらに、要件エンジニアリングにおける要件の引き出しと仕様作成も、ソフトウェア設計と評価の一部と見なすことができます[51][112]。
このセクションでは、ソフトウェア設計と評価におけるLLMsの最近の主な研究成果をレビューし、それらの応用シナリオと実際の効果を議論します。
A. LLMsのタスク
近年、LLMs(大規模言語モデル)の自動化、最適化、およびコード理解などのタスクにおける研究が盛んに行われています。ChatGPTはさまざまなソフトウェア工学のタスクに広く利用され、ログ要約、代名詞解決、およびコード要約といったタスクで優れた性能を示し、ログ要約および代名詞解決タスクの両方で100%の成功率を達成しています[113]。しかし、コードレビューや脆弱性検出のようなタスクでは比較的性能が低く、より複雑なタスクにはさらなる改善が必要であることが示されています。
別のフレームワークであるEvaluLLMは、伝統的な参照ベースの評価指標(例えばBLEUやROUGE)の限界に対処し、自然言語生成(NLG)出力の品質をLLMsを用いて評価します[114]。EvaluLLMは、新しい評価方法を導入し、生成された出力をペアで比較し、勝率指標を使用してモデルの性能を測定します。このアプローチは、評価プロセスを簡略化しつつ、人間の評価と一貫性を確保し、生成タスクにおけるLLMsの広範な応用可能性を示しています。
同様に、LLMs評価の分野では、LLMベースのNLG評価は現在のNLG評価に使用されるLLMsのレビューと分類を提供しており、論文では4つの主要な評価方法:LLM導出指標、プロンプトベースのLLMs、ファインチューニングされたLLMs、および人間とLLMの協力的評価を要約しています[115]。これらの方法は、生成された出力を評価する上でのLLMsの可能性を示し、評価指標の改善や人間とLLMの協力のさらなる探求の必要性といった課題も言及しています。
また、エンジニアリング設計における多くの新しいアプリケーション設計には、LLMsが適用されています。ある研究では、LLMsを最適化するためのハードウェア/ソフトウェア共設計の戦略を探求し、これらの戦略を設計検証に適用しています[116]。量子化、プルーニング、および操作レベルの最適化を通じて、本研究は高レベル合成(HLS)設計機能検証における応用を示しています。GPT-4を使用して事前定義されたエラーを含むHLS設計を生成し、「Chrysalis」と呼ばれるデータセットを作成しました。このデータセットは、LLMベースのHLSデバッグアシスタントの評価と最適化のための貴重なリソースを提供します。最適化されたLLMは推論性能を大幅に向上させ、電子設計自動化(EDA)分野におけるエラー検出と修正の新しい可能性を提供します。
[117]の研究では、RaWiと呼ばれるデータ駆動型GUIプロトタイピング手法を紹介しています。このフレームワークはユーザーがリポジトリからGUIを取得、編集、新しい高精度プロトタイプを迅速に作成できるようにします。RaWiと従来のGUIプロトタイピングツール(Mockplus)を比較する実験を通じて、ユーザーがプロトタイプを作成する速度と効果を測定し、RaWiが精度@kメトリックで40%の改善を示した結果を得ました。この研究は、プロトタイピング段階の効率を向上させるLLMsの可能性を証明し、デザイナーがGUIデザインを迅速に繰り返し、設計の欠陥を早期に検出することを可能にします。
LLMsによってもたらされた新しい可能性に伴い、教育分野でも多くの議論がなされており、研究者は大規模言語モデルの普及が教育に与える影響について探っています[118]。ある研究は、ChatGPTがソフトウェアテストコースの質問に答える際に大きな可能性を示すが、いくつかの制限もあることを示しています[119]。ChatGPTは質問の約77.5%に答えることができ、正解または部分的な正解を55.6%の確率で提供しました。しかし、その説明の正確性は53.0%に過ぎず、教育応用におけるさらなる改善の必要性が示されています。
B. LLMベースのエージェントのタスク
LLMベースのエージェントのソフトウェア設計と評価における応用は、開発の効率とコード品質を向上させ、実際のソフトウェア工学タスクにおける広範な適用可能性と大きな潜在能力を示しています。[120]では、ソフトウェア工学における自律エージェントの現在の能力、課題、および機会を探求しています。この研究では、ソフトウェア開発ライフサイクル(SDLC)の異なる段階(ソフトウェア設計、テスト、GitHubとの統合)におけるAuto-GPTの性能を評価し、詳細なコンテキストプロンプトが複雑なソフトウェア工学タスクのエージェントの性能を大幅に向上させることを発見しました。この論文は、コンテキストリッチなプロンプトの重要性を指摘し、エラーの減少と効率の向上を強調し、LLMベースのエージェントがさまざまなSDLCタスクを自動化および最適化する可能性を示しています。さらに、この論文はAuto-GPTの限界を評価し、タスクや目標のスキップ、不必要なコードやファイルの生成(幻覚)、繰り返しやループの応答、タスク完了検証メカニズムの欠如といった問題を指摘しています。これらの限界は、不完全なワークフロー、正確でない出力、実際のアプリケーションでの不安定なパフォーマンスにつながる可能性があります。
また、[121]はChatDevという最初の仮想チャット駆動型ソフトウェア開発会社を紹介し、LLMsを特定のタスクだけでなく、チャットベースのマルチエージェントフレームワークの中心的な調整役として使用するコンセプトを提案しています。このアプローチは、より構造化され、効率的で協力的なソフトウェア開発プロセスを実現し、チャット駆動型マルチエージェントシステムが効率的なソフトウェア設計と評価を達成し、コードの脆弱性を減少させ、開発効率と品質を向上させる方法を探求しています。実験では、ChatDevが409.84秒の平均でソフトウェアを設計および生成し、コストがわずか$0.2967である一方で、コードの脆弱性を大幅に削減することが示されました。これにより、チャットベースのマルチエージェントフレームワークがソフトウェア開発の効率と品質を向上させる能力が示されています。
さらに、Microsoftの研究チームによって導入された同様の協力フレームワークとして、[122]はLLMs、特にChatGPTをエージェントの制御役として使用し、さまざまなAIタスクを管理および実行する効果を示しています。HuggingGPTシステムは、ChatGPTを使用してHugging Faceに存在するさまざまなAIモデルのタスク実行を調整し、ユーザーの要求に基づいて適切なモデルを実行することにより、言語、ビジョン、および音声タスクなどの複雑なAIタスクをどれだけ効果的に処理できるかをテストします。この革新は、LLMsを直接タスク実行のツールとしてだけでなく、既存のAIモデルを活用して複雑なタスクを実行する中心的な調整役として使用する点にあります。このアプローチは、LLMsの実用性を典型的な言語タスクを超えて拡大させます。
[123]では、動的なマルチエージェント環境におけるLLMsの能力を評価するためのLLMARENAベンチマークフレームワークを提案しており、このアイデアはChatDevに似ていますが、焦点を単一エージェントの静的タスクから動的およびインタラクティブなマルチエージェント環境に移し、より現実的で挑戦的な設定を提供してLLMsの実際の有用性を評価します。これは、複数のエージェント(AIまたは人間)がインタラクトおよび協力する現実の条件を反映しています。実験では、このフレームワークがゲーム環境での空間設計、戦略的計画、およびチームワーク能力をテストでき、多エージェントシステムの設計と評価に新しい可能性とツールを提供することが示されています。
[124]では、AIモデルと人間の間のインタラクションを構造化する「フロー」概念フレームワークを紹介し、推論能力と協力能力を向上させることを目指しています。この研究は、プロセスを独立した目標駆動型エンティティとして概念化し、標準化されたメッセージベースのインターフェースを介してインタラクトすることを提案し、モジュラーで拡張可能な設計を可能にします。このアプローチは、複雑な依存関係を管理することなく、複雑なネストされたAIインタラクションの開発をサポートし、競技コードタスクの実験では、「フロー」フレームワークがAIモデルの問題解決率を21ポイント、AIと人間の協力率を54ポイント向上させることが示されています。これにより、モジュラーデザインがAIと人間の協力を強化し、ソフトウェア設計および評価プロセスを改善する方法が示されています。
[125]は、LLM統合アプリケーションを構造的に理解および分析するための新しい分類法を提示し、ソフトウェア設計および評価のための新しい理論と方法を提供します。この分類法は、ソフトウェアシステムにおけるLLMコンポーネントの統合を理解するのに役立ち、より効果的で効率的なLLM統合アプリケーションを開発するための理論的基盤を提供します。類似して、[126]では、LLMベースのエージェントをソフトウェア保守タスクに適用し、コード品質と信頼性を向上させる協力フレームワークを探求しています。この研究はソフトウェア保守の分野に分類されるべきですが、デザイン構造の反復的な形式を示しています。フレームワークは複雑なエンジニアリングタスクを効果的に処理できない伝統的な一発方法を克服するために、タスク分解およびマルチエージェント戦略を使用しています。複数のエージェントが互いに学習することで、ソフトウェア保守の結果が改善されます。実験では、マルチエージェントシステムが複雑なデバッグタスクで単一エージェントシステムを上回り、この新しいフレームワークが安全なアーキテクチャを提供するためにソフトウェア設計に応用できることが示されています。
C. 分析
全体として、ソフトウェア設計および評価におけるLLM(大規模言語モデル)の応用は、コード生成やログ要約といった特定のタスクの自動化に焦点を当てる傾向があり、設計段階での実装よりも能力の評価に重点を置いています。ソフトウェア設計のプロセスは、ソフトウェア開発および要件エンジニアリングと密接に結びついています。前述のとおり、LLMsを使用してソフトウェア開発を支援する場合、関連する設計文書の生成など、ソフトウェア設計プロセスの側面を含むことがよくあります。このため、高次のソフトウェア設計タスクにLLMsを使用する研究は比較的少ないです。
LLMベースのエージェントは、インテリジェントな意思決定とタスク実行を通じて、より複雑なワークフローを処理することにより、LLMsの能力を拡張します。これらのエージェントは協力し、タスクを動的に調整し、外部情報を収集および活用することができます。ソフトウェア設計および評価では、単一のモデルが設計および評価の両方の側面を包括的に考慮することは難しいため、多くのソフトウェア開発者は高レベルのタスクをAIに委ねることをためらいます。LLMベースのエージェントは、協力作業とより洗練された役割分担を通じて、設計タスクを効率的に完了し、さまざまな応用シナリオに適応できます。
しかし、ソフトウェア設計におけるLLMベースのエージェントの応用は、ソフトウェア開発に組み込まれることが一般的です。前述の通り、設計段階で自己反省や推論が行われます。また、ChatDev [121] フレームワークは役割分担を使用して、ソフトウェア設計フェーズを分離することで、後の開発フェーズでの柔軟性と正確性を大幅に向上させます。
効率とコストの面では、LLMsはテキスト生成および脆弱性検出において依然として若干優れています。しかし、ソフトウェア保守や根本原因分析といったタスクを処理するためには、マルチターン対話、知識グラフ、およびRAG技術(Retrieval-Augmented Generation)などのより複雑なアーキテクチャが必要とされ、これらは設計および評価フェーズにさらに利益をもたらすことができます。
D. ベンチマーク
ベンチマークにはパブリックデータセットと著者自身によって作成されたデータセットが含まれており、その適用シナリオも表 VIII に示されるようにかなり異なります。
BigCloneBenchはコードクローン検出のためのベンチマークデータセットで、多数のJava関数ペアを含んでいます。これらのペアはクローンと非クローンとして分類され、クローン検出モデルのトレーニングと評価に使用され、主な評価指標は正確な識別率です。
Chrysalisデータセットは[116]により作成され、11のオープンソースのシンセサイザブルHLSデータセットから得られた1000以上の関数レベルの設計を含んでいます。主に、HLS設計に注入されたエラーの検出と修正におけるLLMデバッグツールの有効性を評価するために使用され、主な評価指標はエラー検出と修正の有効性です。
CodexGLUEデータセットは、コード補完、コード修正、コード翻訳などの様々なコード生成および理解タスクをカバーする包括的なベンチマークデータセットであり、実際のプログラミングタスクにおけるコード生成モデルの性能を評価するために使用されます。
これらのパブリックデータセットに加えて、仮想ジョブフェア環境データセットなどの人工的にシミュレートされたデータセットも使用されます。このデータセットは面接、採用、チームプロジェクトの調整などの複数のタスクシナリオを含む仮想ジョブフェア環境をシミュレーションします。このデータセットは、複雑な社会的タスクにおける生成エージェントの調整能力を評価するために使用され、主な評価指標はタスク調整成功率と役割マッチングの正確性です。
比較的に、LLMの研究はBigCloneBenchのような特定のパブリックデータセットを使用する傾向があります。これらのデータセットは標準化された評価ベンチマークを提供し、結果の再現性と比較可能性を助けます。LLMベースのエージェントに関する研究は、カスタマイズされた実験設定や未指定のデータセット、例えば、要求ドキュメントを使用する傾向があり、特定のデータセットを指定せずに、実験が70のユーザー要求を含むことを強調することが一般的です。この選択は、研究が複数の角度から性能を評価する必要があるためであり、一般的なデータセットでは特定の適用シナリオに完全に適応するのが難しい場合があるためです。
LLMおよびLLMベースのエージェントの両方は、コード生成、コード理解、自然言語生成、タスク管理などのタスクをカバーする様々なデータセットを使用してモデルの性能を評価しますが、ソフトウェア設計および評価の話題は他の話題と比較的関連性が高いです。しかし、LLMベースのエージェントはビデオや画像などの応用シナリオにも拡張できるため、Auto-GPTやHuggingGPTのようなエージェントはマルチモーダルデータセットも使用します。これらのデータセットはコードとテキストだけでなく、画像や音声などの複数のデータタイプも含みます。
さらに、単一のLLMフレームワークと比較して、LLMベースのエージェントは評価する領域が多いため、ベンチマークも別々に考慮する必要があります。例えば、LLMARENAは動的なマルチエージェント環境でのLLMの性能をテストするために特別に設計されており、空間推論、戦略的計画、リスク評価などの複雑なタスクをカバーしています。
E. 評価指標
ソフトウェア設計および評価において、さまざまな研究がLLMs(大規模言語モデル)およびLLMベースのエージェントのパフォーマンスを測定するために異なる評価指標を採用しています。LLMおよびLLMベースのエージェントの研究はいずれも、モデルのパフォーマンスを包括的に評価するために複数の指標を使用していますが、LLMの研究は伝統的な指標(例えば、精度、勝率、および一貫性)に焦点を当てる傾向があります。一方で、LLMベースのエージェントの研究は、これらの基本的な指標を考慮するだけでなく、タスク調整成功率や役割マッチングの精度などの複雑な評価方法も導入しています。
ただし、将来的にLLMベースのエージェントの研究が常に多次元にわたる柔軟な評価指標を使用するとは限らず、特定のタスクや使用されるデータセットに依存することが多いといえます。この現象の理由は、この調査から観察されたように、LLMの研究が比較的単一のタスクに焦点を当てており、主に伝統的な評価方法を用いた静的なタスク(例:ログ要約)に注力しているためです。一方、LLMベースのエージェントの研究は、より一般的なマルチエージェントタスクを含み、その評価方法はインタラクティブ性と動的性を強調しています。
LLMベースのエージェントの研究は、モデルの協力および意思決定能力に焦点を当て、実際の応用におけるその可能性を包括的に評価するために多次元の評価指標を使用しています。このため、精度や完了時間といった評価指標の類似性があるにもかかわらず、LLMベースのエージェントは相互排他性や適切性などの柔軟な評価指標を使用しています。これにより、モデルが単純な予測精度だけでなく、さまざまな状況での適応能力や協力能力を持つことを確認することができます。
VIII. ソフトウェアテスト生成
ソフトウェア開発において、ソフトウェアテストは非常に重要なコンポーネントであり、初期のシステム開発段階から最終的なデプロイメントまで継続的に実施される必要があります。業界では、アジャイル開発が一般的であり、システムの堅牢性を確保するために各段階で継続的にテストを行います。新しいコードがGitHubにコミットされるたびに、更新バージョンの使いやすさを確認するためのテストが実施されます。一般的なアプローチとしては、Jenkinsを使用して継続的インテグレーション(CI)および継続的デプロイ(CD)を実現することが挙げられます。Jenkinsは、開発者のGitHubへのコードプッシュアクションに自動でフックし、新しいバージョンに対してテストスイートを実行します。
このプロセス全体は自動化に向かっていますが、テストケースの作成および洗練には依然として大きな人的努力が必要です。開発における典型的な役割には、単体テスト、統合テスト、およびファズテストの作成といったソフトウェアテストが含まれます。研究者たちは2000年代前からテストケースの生成を支援するためにAIを活用しようと試みてきました。初期の実装は、テストケース生成プロセスの一部を自動化するためのシンプルな形式のAIや機械学習を使用していました。
時が経つにつれて、自然言語処理や高度な機械学習モデルなどのより洗練された方法が、テストケース生成の精度と範囲を向上するために適用されるようになりました。例えば、アプリケーションのコンテキストに基づいたパスを生成するために機械学習を使用するオンラインツール「Sofy」も存在し、テストスイートの生成を支援しています。
大規模言語モデル(LLM)を使用してテストケースを生成する試みは比較的新しいものですが、急速に発展しています。2020年には、ラベル付きデータで微調整された事前学習済み言語モデルを使用してテストケースが生成されました。研究者たちはシーケンス・ツー・シーケンスのTransformerベースのモデルを開発し、その生成結果をEvoSuiteやGPT-3と比較して、より良いテストカバレッジを示しました [131]。
さらに多くの研究とモデルがテストスイート生成実験に専念しており、例えばコード生成セクションで言及されたCodexモデル [67]は、Chain-of-Thoughtプロンプティングと組み合わせてCodeCoTで高品質なテストスイート生成を達成しており、ゼロショットシナリオでも優れた結果を示しています。
LLMの導入はテストプロセスを自動化し、精緻化することを目的としており、人間が見逃しがちな側面にも対応できるようになります。これにより、テストの厳密性が増し、より効率的で効果的なテストが可能となります。
A. LLMsのタスク
ソフトウェアテスト生成におけるLLMs(大規模言語モデル)の応用は広範であり、単なるテストスイート生成にとどまりません。この調査に含まれるレビュー論文は、セキュリティテスト生成、バグ再現、一般的なバグ再現、ファズ(Fuzz)テスト、およびカバレッジ駆動型テスト生成など、いくつかの側面をカバーしています。これらのタスクはさまざまなモデルや技術によって達成されており、ソフトウェアの品質を大幅に向上させ、開発者の負担を軽減します。
[132]は、GPT-4を使用してセキュリティテストを生成する有効性を評価し、依存関係の脆弱性を悪用するサプライチェーン攻撃の実施方法を示しています。この研究では、異なるプロンプトスタイルとテンプレートを実験して、情報入力の変動がテスト生成品質に与える影響を探求しました。結果は、ChatGPTが生成したテストが55のアプリケーションで24の概念実証脆弱性を成功裏に発見し、既存のツールであるTRANSFER [133]およびSIEGE6を上回ることを示しています。この研究は、LLMsを使用してセキュリティテストを生成する新しい方法を紹介し、セキュリティテスト分野におけるLLMの可能性を実証し、開発者にライブラリの脆弱性に対処する新しいアプローチを提供します。
別の応用としては、バグ再現があります。これにより、テスターはバグをより迅速かつ効率的に特定および修正できます。[134]は、現在のバグ再現方法が手作りのパターンや事前定義された語彙の質と明瞭さに制約されている点をアドレスします。この論文は、Androidバグレポートからエラーを自動的に再現するために、大規模言語モデルを使用した新しいメソッドフレームワークであるAdbGPTを提案し、その性能を評価しています。AdbGPTは、SOTAアプローチを上回る性能を示し、S2Rエンティティ抽出で90.4%および90.8%の正確度を達成し、エラー再現においては81.3%の成功率を示しました。また、AdbGPTはGUIエンコーディングを使用して、GUIビュー階層をHTMLのような構文に変換し、現在のGUI状態を明確に理解させることができます。
AdbGPTがAndroidシステムに特化している一方で、[135]はバグ報告からバグ再現テストを生成するLLMsを利用したLIBROフレームワークを提案しています。実験結果は、LIBROがDefects4Jデータセットで33.5%、GHRBデータセットで32.2%のバグを再現したことを示しています。LIBROは高度なプロンプトエンジニアリングと後処理技術を組み合わせることで、バグ再現テストの生成におけるLLMsの効果と効率を示しています。LIBROはAdbGPTに比べて絶対的な効果は低いものの、より多様なJavaアプリケーションを対象としており、Androidに限定されていません。
LLMsの広範な応用は、セキュリティテスト生成、バグ再現、ファズテスト、プログラム修正、カバレッジ駆動型テスト生成などのタスクにおいて、ソフトウェア品質を向上させ、開発者の負担を軽減する可能性を示しています。これらのタスクは、さまざまなモデルと技術を通じて、LLMsがテストプロセスを自動化および強化し、人間が見落としがちな側面に対応する方法を示しています。
ファズテストでも、LLMsは有望な可能性を示しています。[136]は、LLMsを使用してさまざまなソフトウェアシステムの入力を生成および変異させるユニバーサルファズィングツールであるFuzz4Allを開発しました。このツールは、特定の言語やシステムに密接に結びついた伝統的なファジングツールの問題を解決し、進化する言語機能をサポートできます。実験では、Fuzz4Allがすべてのテストされた言語で最高のコードカバレッジを達成し、平均して36.8%の増加を示し、9つのシステムで98のバグを発見しました。これは、ファズィングにおけるLLMsの効果と、多言語およびシステムでのテストにおける能力を示しています。
[137]は、新しいコード認識プロンプティング戦略としてSymPromptを紹介し、既存の検索ベースのソフトウェアテスト(SBST)方法と伝統的なLLMプロンプティング戦略の限界を克服して、高カバレッジのテストケースを生成します。実験結果は、SymPromptがCodeGen2とGPT-4でそれぞれ26%および105%のカバレッジ向上を示しています。
[138]もテストスイートカバレッジに焦点を当て、この研究はLLMsと相互作用することで高カバレッジのPython回帰テストを生成するCOVERUPシステムを紹介しました。実験結果は、COVERUPがコードカバレッジを62%から81%に、ブランチカバレッジを35%から53%に向上させたことを示しています。
[139]は、LLMsを差分テストと組み合わせて「おそらく正しい」ソフトウェアのフォールト検出を改善するAID方法を提案しています。実験では、AIDがフォールトを発見するテスト入力とオラクルを生成する効果が、リコールと精度をそれぞれ1.80倍および2.65倍改善し、F1スコアを1.66倍向上させました。これにより、LLMsの強力なフォールト検出能力が示されています。
B. LLMベースのエージェントのタスク
ソフトウェアテスト生成の分野において、LLMベースのエージェントの応用は、自動化されたテスト生成におけるその潜在能力を示しています。ソフトウェアテスト生成のためにLLMベースのエージェントを利用することは過剰に思えるかもしれませんが、多くの研究が脆弱性検出やシステムメンテナンスに向けられています。LLMベースのエージェントは、テスト生成、実行、最適化といったタスクを分散させることで、テストの信頼性と品質を向上させることができます。これらのマルチエージェントシステムは、エラー検出と修正、およびカバレッジテストにおいて明らかな改善をもたらします。
例えば、AgentCoderのマルチエージェントフレームワークは、コード生成およびソフトウェア開発セクションで取り上げられました[82]。このシステムの主な目標は、複数の専門エージェントを活用してコード生成を反復的に最適化し、単一エージェントモデルの限界を克服することです。テスト設計エージェントが多様で包括的なテストケースを作成し、テスト実行エージェントがテストを実行してフィードバックを提供することで、このシステムはMBPPデータセットで89.9%の合格率を達成しました。
同様に、SocraTestフレームワークは自律学習および意思決定のトピックに該当します[106]。このフレームワークは会話的なインタラクションを通じてテストプロセスを自動化し、GPT-4を使用したテストケースの生成および最適化の詳細な例を示しています。試験結果は、会話型LLMsを通じてSocraTestが効果的にテストケースを生成および最適化し、ミドルウェアを使用してLLMとさまざまなテスティングツールとの間でインタラクションを促進することができ、自動化されたテスト能力を向上させることを示しました。
ソフトウェアテスト生成のトピックに関連する論文は、ほとんどがマルチエージェントベースのシステムに基づいています。研究[140]では、LLMsが高品質なテストケースを生成する効果を評価し、その限界を特定しています。この研究では、TestChainという新しいマルチエージェントフレームワークを提案しています。この論文は、StarChat、CodeLlama、GPT-3.5、およびGPT-4をHumanEvalおよびLeetCode-hardデータセットで評価しました。実験結果は、TestChainフレームワークがGPT-4を使用してLeetCode-hardデータセットで71.79%の精度を達成し、ベースライン方法より13.84%の改善を示しました。HumanEvalデータセットでは、TestChainがGPT-4を使用して90.24%の精度を達成しました。TestChainフレームワークは、エージェントが多様なテスト入力を生成し、ReActフォーマットのダイアログチェーンを使用して入力を出力にマッピングし、Pythonインタープリターと対話して正確なテスト出力を得るように設計されています。
LLMベースのエージェントはユーザー受け入れテスト(UAT)にも適用できます。[141]は、WeChat Pay UATプロセスの自動化を強化するために、テストスクリプトを自動生成するためのLLMsを使用するマルチエージェント協調システムXUAT-Copilotを提案しています。この研究では、WeChat Pay UATシステムから450のテストケースを使用して、XUAT-Copilotの性能を単一エージェントシステムおよびリフレクションコンポーネントを含まないバリアントと比較しています。実験結果は、XUAT-CopilotがPass@1率で88.55%を達成し、単一エージェントシステムの22.65%およびリフレクションコンポーネントを含まないバリアントの81.96%を上回り、Complete@1率では93.03%を達成しました。XUAT-Copilotは、アクションプランニング、ステートチェック、パラメータ選択エージェントを含むマルチエージェント協調フレームワークを採用し、先進的なプロンプティング技術を使用しています。XUAT-Copilotは、UATテストスクリプト生成の自動化におけるLLMsの潜在能力と実現可能性を示しています。
C. 分析
比較してみると、LLMs (大規模言語モデル) は単一タスクの実装において優れた性能を発揮し、プロンプトエンジニアリングやfew-shot学習の技術を通じて高品質なテストケースを生成しています。LLMsの能力が向上するにつれて、関連する研究の数も増加しています。その一方で、LLMベースのエージェントはマルチエージェントの協調システムを通じてタスクを分解し、専門的な処理を行うことで、反復的な最適化とフィードバックによってテスト生成と実行の効果と効率を大幅に向上させます。
コストを考えると、テスト生成のみにLLMsを使用する方が十分であり、LLMベースのエージェントを使用するよりもコストが節約できます。しかし、特定のモデルの性能が低い場合、それがシステム全体のパフォーマンスに影響を与える可能性があります。単一のLLMは、複雑なマルチステップタスクには苦戦するかもしれません。高カバレッジのテスト生成では、必要な結果を達成するためにより複雑なプロンプトや後処理ステップが必要になる場合があります。さらに、生成された結果の品質は、プロンプトの設計や品質に大きく依存します。細かい制御や継続的な最適化が必要なタスクには、単一のLLMでは対応が難しいかもしれません。
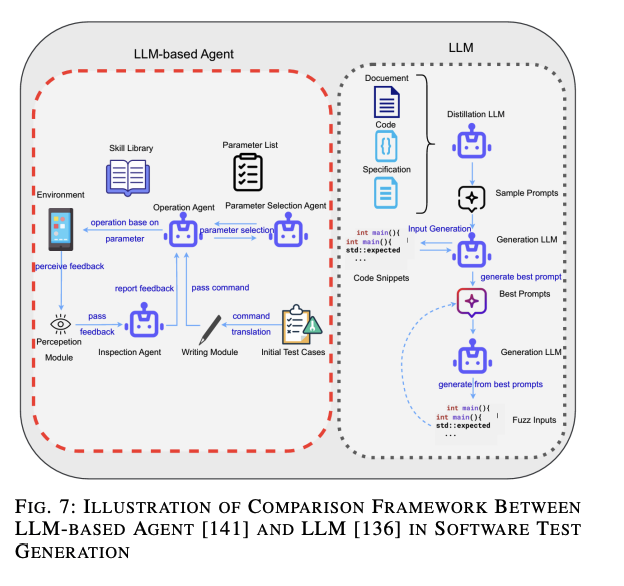
図??に示されるように、LLMフレームワークはファズテストにおけるLLMsの使用法を示すために[136]を例にとって説明しています。プロンプトはコードスニペット(ファズ入力)によって最適化され、LLMによって再度最適なプロンプトが選択され、将来の生成に役立てられます。全体的なフレームワークは自律性に欠けており、左側のLLMベースのエージェント[141]フレームワークがこのギャップを埋め、UIを認識し、操作のためのスキルライブラリとインタラクトできます。操作エージェントは検査エージェントから報告されたエラーを受け取り、自動的にプロセスを洗練する自己反省を行います。
しかし、前述のように、ソフトウェアテスト生成タスクのために専用のLLMベースのエージェントフレームワークを構築することは「過剰な出費」となります。そのため、LLMベースのエージェントシステムに関する論文は、一般的に生成されたテストケースやバグ再現システムを用いたプログラム修正に焦点を当てています。図??では、LLMベースのエージェントフレームワークがWeChat Payシステムを自動テストするために実際に使用されていることが示されています。
D. ベンチマーク
ソフトウェアテスト生成におけるLLMs(大規模言語モデル)のタスクにおいて、使用されるデータセットにはDefects4Jが含まれており、これはバグ再現およびプログラム修正技術を評価するために使用されます。他のパブリックデータセットとしては、ReCDroid、ANDROR2+、Themisがあり、これらは主にモバイルアプリケーションのバグ再現およびセキュリティテスト生成を評価するために使われ、特にAndroidプラットフォーム向けのものです。GCC、Clang、Goツールチェーン、Javaコンパイラー(javac)、およびQiskitは、さまざまなプログラミング言語およびツールチェーン向けのファズテストデータセットを含んでおり、マルチランゲージ環境でのファズテストの効果を評価することを目的としています。TrickyBugsおよびEvalPlusは複雑なバグシナリオを含むデータセットであり、生成されたテストケースの精度およびリコールを評価するために使用されます。CODAMOSAが評価するベンチマークアプリケーションは、カバレッジベースのテスト生成ツールの効果を評価するために用いられます。
LLMベースのエージェント研究で使用されるデータセットも非常に一般的です。HumanEval、MBPP、およびLeetCode-hardは、コード生成およびテスト生成の精度およびカバレッジを評価するために使用されており、さまざまなプログラミング問題および課題を含んでいます。これらは、前述のセクションに頻繁に登場しています。Codeflaws、QuixBugs、ConDefectsのようなデータセットは、エラーが含まれたコードやプログラムをLLMsに馴染ませるために収集されており、複数のプログラムエラーおよび欠陥を含んでいます。これらは、自動デバッグおよびバグ修正の効果を評価するために使用されます。
特定のデータセットとしては、WeChat PayのUATシステムがあります。これは実際のアプリケーションからのユーザー受け入れテストケースを含んでおり、ユーザー受け入れテストにおけるマルチエージェントシステムの性能を評価するために使用され、特にWeChatのセキュリティシステムに焦点を当てています。
全体として、LLMベースのエージェント研究で使用されるデータセットは、広範なプログラミング問題および課題をカバーしており、LLMの研究は主にバグ再現やマルチランゲージ環境でのファズテストといった実際の生成タスクに焦点を当てています。これは、LLMベースのエージェントが生成されたテストケースやコードの品質だけでなく、マルチエージェントシステムの協力効果と反復最適化能力も評価するためです。そのため、ベンチマークにはフレームワークの性能を評価するために使用されるデータセットも含まれています。例えば、AgentCoder [82]はMBPPやHumanEvalを使用して評価を行い、マルチエージェント協力によってテスト生成および実行の効率と精度を向上させました。LLMベースのエージェント研究は、定性的評価やユーザーフィードバックを通じてシステムの効果を検証することに重点を置いています。
E. 評価指標
表 IXに示されるように、LLMs(大規模言語モデル)の研究は主にバグ再現率、コードカバレッジ、精度、再現率といった伝統的な定量的指標を使用しており、これらの指標はテスト生成の効果と品質を直接反映しています。これに対して、LLMベースのエージェントの研究では定量的指標に加え、会話型インタラクションやマルチエージェントシステムの協働効果などの定性的評価も導入しています。これは、システムの実用的な応用効果をより包括的に反映するための多角的な評価アプローチです。
タスクの観点から見ると、LLMsは通常、テストセットの生成や生成されたテストセットのカバレッジを考慮する単一タスク処理に向いています。一方、エージェントフレームワークの拡張のために、LLMベースのエージェントは生成されたテストセットを使用して脆弱性を見つけるかどうかを評価し、より理想的な実用性を追求する傾向があります。
設計の観点から見ると、LLMシステムはプロンプトエンジニアリングやモデルの生成能力に依存しており、その評価指標もモデルの出力の質と効果に主に焦点を当てています。評価指標には、マルチエージェントの協働効果とシステム内の効率も含まれており、例えばマルチエージェント協働を通じてPass@1およびComplete@1のレートを向上させることがあります。
全体として、LLMsは特定のタスクに対する迅速なテスト生成と評価に適しており、評価指標は生成の効果と品質を直接反映しています。LLMベースのエージェントは、複雑で多様なタスクを処理するのに優れ、マルチエージェント協働と反復最適化を通じてシステムの効率と効果を高めています。
IX. ソフトウェアセキュリティとメンテナンス
ソフトウェア工学において、ソフトウェアセキュリティとメンテナンスはLLMs(大規模言語モデル)の応用で人気の高い分野であり、主に既存の技術を通じてソフトウェアシステムのセキュリティと安定性を向上させ、ユーザーと開発者のニーズに応えることを目的としています。これらのモデルは、脆弱性の検出と修復の有望な方法を提供し、セキュリティテストの自動化と革新的なメンテナンスプロセスを可能にします。
LLMsのソフトウェアセキュリティとメンテナンスへの応用は、脆弱性検出、自動修復、ペネトレーションテスト、およびシステムの堅牢性評価などの複数の側面をカバーしています。従来の方法と比較して、LLMsは自然言語処理と生成技術を活用して複雑なコードやセキュリティポリシーを理解・生成し、検出および修復タスクを自動化します。例えば、LLMsはコード構造とコンテキスト情報を解析することで潜在的な脆弱性を正確に特定し、対応する修復提案を生成して脆弱性の修復の効率と精度を向上させることができます。
さらに、LLMsは脆弱性検出だけでなく、ペネトレーションテストやセキュリティ評価のタスクにも強力な能力を発揮します。例えば、自動ペネトレーションテストツールとしてPENTESTGPT [143]があります。LLMsはさまざまな攻撃シナリオをシミュレートすることでシステムのパフォーマンスを評価し、異なる条件下でのシステム性能を評価することで、開発者が潜在的なセキュリティ問題をより良く特定し対処するのに役立ちます。
ソフトウェアセキュリティとメンテナンスにおけるLLMベースのエージェントの研究も成長を続けています。これらのインテリジェントエージェントは、複雑なコード生成および脆弱性修復タスクを実行し、動的な開発環境で遭遇する問題を処理する自己学習および最適化能力を備えています。例えば、RITFIS [144]やNAVRepair [145]のようなツールは、LLMベースのエージェントを使用してプログラム修復の精度と効率を向上させる可能性を示しています。
応用例
脆弱性検出と修復
LLMsはコードの文脈情報を理解し、潜在的な脆弱性を特定し、修復提案を生成する機能があります。これにより、脆弱性の検出と修復の効率と精度が向上します。
ペネトレーションテスト
LLMsを利用した自動ペネトレーションテストツール(例:PENTESTGPT)は、さまざまな攻撃シナリオをシミュレートしてシステムのセキュリティを評価する機能を持ちます。
システム堅牢性評価
LLMsは、異なる条件下でのシステムのパフォーマンスを評価することで、潜在的なセキュリティ問題を特定し対処するのに役立ちます。
LLMベースのエージェント
RITFISやNAVRepairなどのツールは、自己学習および最適化能力を備えたLLMベースのエージェントを使用して、プログラム修復の精度と効率を向上させています。
LLMsおよびLLMベースのエージェントは、ソフトウェアセキュリティとメンテナンスの分野で多くの可能性を秘めており、関連する技術とツールの開発が進むにつれて、ますます多くの実用的な応用が期待されています。
A. LLMsのタスク
ソフトウェアセキュリティとメンテナンスの分野におけるLLMs(大規模言語モデル)の研究は、主に脆弱性検出、自動修復、ペネトレーションテストの三つの主要な領域に分類されると共に、評価研究も含みます。これらの領域におけるLLMsの多様な応用とその可能性が収められた論文が多数存在します。
1. プログラム脆弱性
脆弱性検出の分野では、LLMsの微調整によってソースコードの脆弱性検出の精度を向上させることが研究されています。
- [146]では、LLMsをソースコードの脆弱性検出に応用する可能性を調査し、CodeBERTのようなモデルの性能限界が容量とコード理解能力に依存しているかどうかを明らかにしようとしました。この研究では、WizardCoderモデル(StarCoderの改良版)を微調整し、その性能をContraBERTモデルと比較しました。実験結果は、バランスの取れたおよびバランスの取れていないデータセットの両方において、WizardCoderがROC AUCとF1スコアの両方でContraBERTを上回り、Java関数の脆弱性検出性能を向上させました。具体的には、CodeBERTの時点では0.66だったROC AUCを0.69に改善し、当時の最先端の性能を達成しました。
- 一部の研究は、フレームワークアーキテクチャを使用せずに純粋にLLMsを応用することで脆弱性検出の限界を探求しています。[147]では、Javaコードの脆弱性検出におけるChatGPTおよびGPT-3モデルの性能を評価し、text-davinci-003(GPT-3)およびgpt-3.5-turboをバイナリおよびマルチラベル分類タスクにおけるベースライン仮想分類器と比較しました。実験結果は、text-davinci-003とgpt-3.5-turboがバイナリ分類タスクにおいて高い精度と再現率を持つ一方で、AUC(Area Under Curve)スコアは0.51に留まり、ランダムな推測相当の性能を示しました。マルチラベル分類タスクにおいても、GPT-3.5-turboとtext-davinci-003は全体的な正確性およびF1スコアでベースライン仮想分類器を大幅に上回ることはありませんでした。これらの結果は、GPT-3のような初期モデルが実際の脆弱性検出タスクにおいて限られた能力しか持たないことを示しており、実用的なアプリケーションにおける性能を向上させるためにはさらなる研究とモデルの最適化が必要であることを示唆しています。LLMsの微調整と最適化により、ソースコード脆弱性検出の性能は大幅に向上する可能性がありますが、実用的なアプリケーションには依然として多くの課題が残されています。
- [148]では、複雑なコード構造を直接モデルの学習プロセスに組み込む方法が紹介されました。GRACEフレームワークはグラフ構造情報とコンテキスト学習を組み合わせ、コードプロパティグラフ(CPG)を使用してコード構造情報を表現します。これにより、コードのセマンティック、構文的、語彙的な類似性を統合し、テキストベースのLLM分析の限界を克服し、脆弱性検出タスクの精度と再現率を向上させます。研究は3つの脆弱性データセットを使用し、ベースラインモデルに比べてF1スコアが28.65%向上しました。
- [149]では、特定のタスクに対してLLMsを微調整し、既存モデル(例:ContraBERT)と比較してその性能を評価しました。研究者たちは、最適なモデルアーキテクチャ、トレーニングハイパーパラメータ、および損失関数を決定する多くの実験を行い、脆弱性検出タスクの性能を最適化しました。主にWizardCoderとContraBERTに焦点を当て、バランスの取れたおよびバランスの取れていないデータセットでそれらの性能を検証し、トレーニング速度を向上させる効率的なバッチパッキング戦略を開発しました。結果は、適切な微調整と最適化が行われた場合、LLMsが最先端モデルを上回る可能性があることを示し、より堅牢で安全なソフトウェア開発の実践に貢献しました。
これらの研究は、ソフトウェアセキュリティとメンテナンスにおけるLLMsの多様な応用可能性を示しており、脆弱性検出から自動修復、ペネトレーションテストに至るまで、多岐にわたるタスクにおいてその効果と利便性を実証しています。
2. 自動プログラム修正(Automating Program Repair)
ソフトウェアセキュリティとメンテナンスの分野では、LLMs(大規模言語モデル)は脆弱性検出だけでなく、自動プログラム修正にも広く応用されています。このセクションでは、その具体的な応用と研究の詳細を述べます。
実際的な効果の調査
[150]の研究では、コード言語モデル(code LMs)がソフトウェアの脆弱性を検出する効果を調査し、既存の脆弱性データセットおよびベンチマークに重大な欠陥があることを指摘しました。研究者は、PRIMEVULという新しいデータセットを開発し、それを使用して実験を行いました。これにより、BigVulなどの既存のベンチマークとPRIMEVULを比較し、GPT-3.5やGPT-4などの最先端のベースモデルを含む複数のコードLMを評価しました。結果は、既存のベンチマークがコードLMの性能を大幅に過大評価していることを示しています。例えば、7BモデルはBigVulで68.26%のF1スコアを獲得しましたが、PRIMEVULではわずか3.09%にとどまり、現在のコード言語モデルの性能と実際の脆弱性検出の要件とのギャップを明らかにしています。
ラウンドトリップ翻訳 (RTT) を使用したプログラム修正
自動プログラム修正の領域では、LLMsはRTT(Round-Trip Translation)を使用して、コードを他の言語に翻訳し、それを元の言語に戻すことで可能なパッチを生成する方法が提案されています。この研究では、さまざまな言語モデルとベンチマークを使用してRTTの性能を評価しました。実験では、プログラミング言語を中間表現として使用した場合と、自然言語(英語)を中間表現として使用した場合のRTTの性能を比較し、修正候補の定性的な傾向を観察しました。結果は、複数のベンチマークでRTTが顕著な修正効果を達成し、特にコンパイルおよび実行可能性の面で優れていることを示しました[151]。
C/C++ コード脆弱性に対するNAVRepairの応用
自動プログラム修正において、[145]はNAVRepairと呼ばれる革新的な方法を紹介しました。NAVRepairは、ノードタイプ情報とエラータイプを組み合わせることでC/C++コードの脆弱性を修正します。このフレームワークはAST(抽象構文木)を使用してノードタイプ情報を抽出し、それをCWEから派生した脆弱性テンプレートと組み合わせてターゲット修正を提案します。この研究は、ChatGPT、DeepSeek Coder、Magicoderなどの人気のあるLLMを使用してNAVRepairの性能を評価し、既存の方法と比較して26%の修正精度の向上を達成しました。
MOREPAIRフレームワークによるパフォーマンス向上
既存の微調整方法の二大制限である、コード変更の背後にある論理的な理由の欠如と、ラージデータセットを微調整する際の高い計算コストに対処するために、[152]はMOREPAIRフレームワークを導入しました。このフレームワークは、構文コード変換とコード変更の論理的な推論を同時に最適化することで、APR(Automated Program Repair)におけるLLMsの性能を向上させます。研究では、微調整の効率を向上させる技術としてQLoRA(Quantized Low-Rank Adaptation)[153]やNEFTune(Noisy Embedding Fine-Tuning)[154]を使用しました。実験では、CodeLlama-13B、CodeLlama-7B、StarChatalpha、およびMistral-7Bの4つの異なるサイズとアーキテクチャのオープンソースLLMを使用し、evalrepair-C++およびEvalRepair-Javaの2つのベンチマークで性能を評価しました。結果は、CodeLlamaがevalrepair-C++およびEvalRepair-Javaの最初の10修正提案でそれぞれ11%と8%の改善を示しました。
自動修正システムPyDexの紹介
もう一つの研究では、PyDexシステムが紹介され、これはLLMsを使用してPythonの初歩的なプログラミング課題における構文および意味論的エラーを自動的に修正します。PyDexはマルチモーダルプロンプトと反復クエリ方法を組み合わせて修正候補を生成し、few-shot学習を使用して修正精度を向上させます。PyDexは、Pythonの入門プログラミングコースから286の実際の学生プログラムで評価され、3つのベースラインと比較しました。結果は、PyDexが既存のベースラインと比較して修正率と効果率を大幅に向上させたことを示しました[155]。
これらの研究は、LLMsが自動プログラム修正の分野で持つ多様な応用可能性とその利便性を示しており、ソフトウェア開発の効率と品質を大幅に向上させる潜在力を持っています。
3. ペネトレーションテスト(Penetration Testing)
LLMs(大規模言語モデル)は、ペネトレーションテストの分野にも応用されており、自動化されたペネトレーションテストの効率と効果を向上させるために使用されています。この分野は脆弱性検出や自動修正ほど頻繁には研究されていませんが、このレビューには関連する2つの論文が含まれています。
PENTESTGPTによるペネトレーションテスト
[143]では、LLM駆動の自動ペネトレーションテストツールPENTESTGPTの開発と評価を行っています。この研究の主要な目的は、LLMsの実際のペネトレーションテストタスクにおける性能を評価し、ペネトレーションテストプロセス中のコンテキスト損失の問題に対処することです。この論文では、PENTESTGPTの3つの自己交互作用モジュール(推論、生成、および解析)を紹介し、13のターゲットと182のサブタスクを含むベンチマークに基づく実証研究を提供します。GPT-3.5、GPT-4、Bardのペネトレーションテスト性能を比較した結果、PENTESTGPTのタスク完了率は、GPT-3.5に比べて228.6%、GPT-4に比べて58.6%高いことが示されました。この研究は、LLMsが自動ペネトレーションテストにおいて持つ潜在能力を実証し、セキュリティ脆弱性の特定と解決を助けることで、ソフトウェアシステムのセキュリティと堅牢性を向上させることを示しています。
ジェネレーティブAIによるペネトレーションテスト
類似の研究論文で、ジェネレーティブAIのペネトレーションテストへの応用を探るものがあります。[158]は、ジェネレーティブAIツール(特にChatGPT 3.5)を使用したペネトレーションテストの有効性、課題、および潜在的な結果を評価しています。この研究では、VulnHubの脆弱性のあるマシンに対する実際の適用実験を通じて、偵察、スキャニング、脆弱性評価、エクスプロイト、およびレポート作成の5つのステージでペネトレーションテストを実施します。この研究は、Shell GPT(sgpt)とChatGPTのAPIを統合して、ペネトレーションテストプロセスでのガイドの自動化を行っています。実験結果は、ジェネレーティブAIツールがペネトレーションテストのプロセスを大幅に高速化し、正確で有用なコマンドを提供することでテストの効率と効果を向上させることを示しています。この研究は、責任ある使用と人間の監視の重要性を強調し、潜在的なリスクと意図しない結果を考慮する必要があることを示しています。
システムの堅牢性評価(Robustness Evaluation)
システムの堅牢性を評価することも開発の重要な部分であり、LLMsは新しいテストフレームワークの開発と評価に使用され、インテリジェントソフトウェアの堅牢性を検出し改善する役割を果たしています。
RITFISによる堅牢性評価
[144]は、自然言語入力に対するLLMベースのインテリジェントソフトウェアの堅牢性を評価するために設計された堅牢入力テストフレームワークRITFISを紹介しています。この研究は、17の既存DNNテスト手法をLLMシナリオに適応させ、複数のデータセットでの実証的検証を行い、現在のLLMソフトウェアの堅牢性の欠陥と限界を明らかにしています。研究結果は、RITFISがLLMソフトウェアの堅牢性を効果的に評価し、複雑な自然言語入力を処理する際の脆弱性を明らかにすることを示しています。この研究は、LLMベースのインテリジェントソフトウェアにおける堅牢性テストの重要性を強調し、実用アプリケーションでの信頼性とセキュリティを向上させるためのテスト手法の改善に向けた方向性を提供しています。
B. LLMベースのエージェントのタスク
LLMベースのエージェントは、自律的な意思決定、タスク固有の最適化、およびマルチエージェントの協力分野で主に応用されており、これらのフレームワークは高度な防御能力を示しています。
デバッグと脆弱性検出
- LDB (Large Language Model Debugger): [159]は、生成されたプログラムを不可分なエンティティとして扱う従来のデバッグ方法の制限に対応するために、プログラムを基本ブロックに分割し、タスクの説明に基づいて各ブロックの正確性を検証することで、人間のデバッグに近い詳細で効果的なデバッグツールを提供しています。HumanEvalベンチマークでの実験結果では、LDBの正確性がベースラインの73.8%から82.9%に向上し、9.1%の改善を示しました。
- ACFIX(アクセスコントロール脆弱性修正): [160]は、スマートコントラクトのアクセスコントロール(AC)脆弱性を自動的かつ適切に修正するための課題に対処します。この論文では、一般的なRBAC(Role-Based Access Control)実践を掘り下げ、LLMを組み合わせることで、AC脆弱性の修正フレームワークを作成しています。実験結果は、GPT-4の52.54%に対して、ACFIXが94.92%の修正率を達成したことを示しています。
- GPTLENS: [161]は、生成と判別の2段階を通じて脆弱性検出精度を向上させるための二段階逆対抗フレームワークを導入しています。GPTLENSは、スマートコントラクト脆弱性の検知において76.9%の成功率を達成しており、従来の方法の38.5%を上回っています。
- 自動修正システムFixAgent: [142]は、故障位置特定、修正生成、およびエラー分析をLLMベースのマルチエージェントシステムを通じて改善する自動デバッグフレームワークであるFixAgentを開発および評価しました。Codeflaws、QuixBugs、およびConDefectsデータセットでFixAgentの性能を評価し、最先端のAPRツールやLLMsと比較しています。実験結果は、FixAgentがQuixBugsデータセットで79バグのうち78を修正し、そのうち9は以前修正されていなかったバグでした。
- RepairAgent: [46]は、動的にプロンプトを生成し、ツールを統合してソフトウェアバグを自動的に修正するエージェントを導入しています。この研究は、現在のLLMベースの修正技術の限界に対処し、モデルがバグやコードに関する包括的な情報を収集することを許容しない固定プロンプトやフィードバックループに代わる方法を提供しています。RepairAgentは、Defects4Jベンチマークで186のバグを修正し、そのうち164が正確に修正され、既存の修正技術を上回る性能を達成しています。
ペネトレーションテスト
- GPT-4を使用したペネトレーションテスト: [109]は、公開されているがパッチが適用されていない脆弱性を自動的に悪用するためのGPT-4の使用を調査し、実験結果は、CVE記述を提供されたときに脆弱性の悪用に87%の成功率を達成したことを示しています。
- 高レベルのタスク計画と低レベルの脆弱性発見の自動化: [107]では、GPT-3.5を使用してペネトレーションテスターを支援することにより、高レベルのタスク計画と低レベルの脆弱性発見の自動化を実現し、ペネトレーションテスト能力を強化しています。この研究は、自動化によって複数のペネトレーションテストのステージを成功裏に実行し、その効果を示しました。
ソフトウェア修正
- SRepairフレームワーク: [157]は、新しいLLMベースのAPR技術「SRepair」を紹介し、修正提案モデルとパッチ生成モデルを組み合わせたデュアルLLMフレームワークを使用しています。その結果、Defects4Jデータセットで従来の技術を85%以上上回る性能を達成しました。
- デュアルエージェントフレームワーク: [162]は、宣言的仕様の修正の自動化と精度を反復プロンプト最適化とマルチエージェント協力を通じて改善するデュアルエージェントフレームワークを提案しています。実験結果は、Alloy4Funベンチマークで231の欠陥を修正し、従来のツールを上回る性能を示しています。
ソフトウェアセキュリティ
- TrustLLMフレームワーク: [108]は、スマートコントラクト監査の精度と解釈可能性を向上させるためにLLMの能力を特定のスマートコントラクトコードの要件に合わせてカスタマイズしたTrustLLMフレームワークを紹介しています。実験結果は、TrustLLMが他のモデルを上回るF1スコア91.21%と精度91.11%を達成しました。
- 安全性解析の複雑なハイブリッド戦略: [163]は、ソフトウェアシステムの信頼性とセキュリティを確保するための複雑なハイブリッド戦略を提案し、LLMベースのエージェントが安全性解析に関連するタスクを実行するためにシステムモデル図と対話するアプローチを説明しています。
これらの研究は、LLMベースのエージェントの様々なアプリケーションを通じて、ソフトウェアセキュリティとメンテナンスにおける潜在的なメリットを示しています。
C. 分析
全体として、LLMベースのエージェントの方向性は、ソフトウェアセキュリティとメンテナンスにおける重要な革新的進展を示しており、全ての分野で改善をもたらしています。以下に、LLMベースのエージェントと従来のLLMアプローチの比較を示します。
デバッグ作業における改善
LLMベースのエージェントは、マルチエージェントの協力とランタイム情報の追跡を通じてデバッグ作業を支援します。従来のLLMアプローチは、与えられたコードスニペットやプログラムをデバッグするために固定プロンプトまたはフィードバックループに依存することが多いです。
- 例: LDB(Large Language Model Debugger)はプログラムを基本ブロックに分割し、各ブロックの正確性を検証することで人間のデバッグ作業に近づけています[159]。
脆弱性検出の効率化
LLMベースのエージェントは、RBAC(Role-Based Access Control)の実践と複雑なコード構造の詳細な学習を組み合わせることで、脆弱性の検出精度と効率を向上させます。従来のLLM方法は、タスクを処理する際に広範な手動の介入と詳細なガイダンスに依存することが多いです。
- 例: ACFIXはRBAC実践を掘り下げた新しい方法を導入し、GPT-4に基づいたプライマリモデルで高い修正成功率を達成しました[160]。
ペネトレーションテストにおける効果
LLMベースのエージェントは、高レベルのタスク計画と低レベルの脆弱性探索を自動化することで、ペネトレーションテストの能力を強化しています。これに対して、従来のLLM方法は、受動的な検出と分析に適しており、能動的なテストと防御能力には欠けています。
- 例: PENTESTGPTはGPT-4を使用してペネトレーションテストを自動化し、従来の方法よりも高いタスク完了率を達成しました[143]。
修正プロセスの自動化と精度
LLMベースのエージェントは、マルチエージェントフレームワークと動的分析ツールを通じてソフトウェアエラーの検出と修正の自動化と精度を向上させます。従来のLLM方法もさまざまなメンテナンスやデバッグタスクで良好な性能を示しますが、修正プロセス中の自律的な意思決定と動的調整能力が欠けています。
- 例: RepairAgentは、情報収集と自己反省フェーズを組み合わせることで、修正の精度を向上させています[46]。
ソフトウェアセキュリティの向上
インテリジェントエージェントは、LLMとセキュリティエンジニアリングモデルを組み合わせることでセキュリティ分析と設計プロセスを改善し、ソフトウェアシステムの信頼性とセキュリティを向上させます。LLMのみを使用する場合、静的分析に依存し、適応性と最適化能力に欠けるため、最適な結果が得られないことがあります。
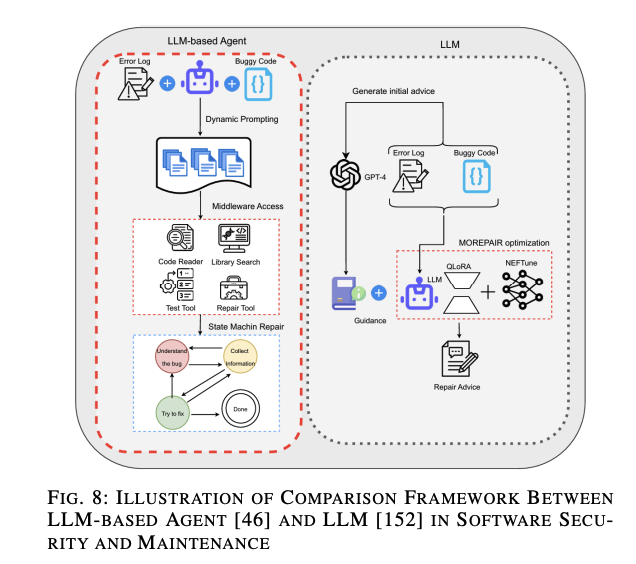
詳細な例:MOREPAIRとRepairAgentの比較
図8に示されているように、LLMフレームワークとしてのMOREPAIR [152]とLLMベースのエージェントとしてのRepairAgent [46]の比較を行います。MOREPAIRはQLoRAおよびNEFTuneといった最適化技術を使用して修正提案を生成します。一方、RepairAgentは複数のツールを使用して分析の精度を高めた後、修正プロセスに進むための「アクション前の推論」的なアプローチを取っています。エージェントフレームワークは状態機械とLLMを使用して継続的に洗練し、修正プロセスが失敗した場合は自己反省フェーズに入って自律的に理由を理解します。
これにより、LLMベースのエージェントはソフトウェアセキュリティとメンテナンスの分野において、より多くの自律性と柔軟性をもたらし、タスクの実行効率と精度を向上させるとともに、複雑なソフトウェア工学タスクの応用範囲を広げることができます。これらの改善は、能動的な防御、複雑なタスク処理、高い信頼性要件を満たす強力な潜在能力を示しています。
D. ベンチマーク
LLMsの文献で使用されるベンチマークを分析すると、いくつかのパブリックデータセットが頻繁に使用され、さまざまな応用シナリオでの存在が際立っています。以下に、いくつかの主要なデータセットとその用途を示します。
脆弱性検出およびソフトウェアセキュリティ
- Defects4J:
- Codeflaws:
- QuixBugs:
- Common Vulnerability and Exposure (CVE)データベース:
自動プログラム修正、宣言仕様の修正
- ARepair:
- 使用例: [162]
- 特徴: このデータセットは、フォーマル仕様を理解し修正するLLMsの能力をテストします。
- HumanEvalおよびMBPP:
- 特徴: 生成されたコードの機能の正確性を評価するために頻繁に使用されています。これらのデータセットは、LLMsのコード生成能力を評価する標準的な指標となっています。
- Alloy4Fun:
ペネトレーションテストおよびスマートコントラクトのセキュリティ
- VulnHubおよびHackTheBox:
- 使用例: [107]
- 特徴: リアルワールドのハッキングシナリオをシミュレートする環境を提供し、LLMsがサイバーセキュリティにおいて実際的な応用能力を持つかどうかを評価します。
- Etherscanから抽出されたスマートコントラクトデータセットおよびSmartFix向けにコンパイルされたデータセット:
比較と結論
LLMとLLMベースのエージェント研究のベンチマークを比較すると、いくつかの主要な類似点と違いが浮かび上がります。両アプローチともDefects4J、CVE、HumanEvalなどのデータセットを頻繁に使用しており、ソフトウェア工学タスクの評価において基本的な役割を果たしています。
しかし、LLMベースのエージェント研究は、VulnHubやHackTheBoxのような専門的なベンチマークを組み合わせて使用することが多く、特にサイバーセキュリティの文脈でより動的かつインタラクティブな能力をテストします。これらのデータセットは、情報の知識だけでなく、リアルワールドシナリオで自律的に適用する能力をテストしています。一方、従来のLLM研究は、リアルタイムのインタラクションや意思決定を必要とすることなく、脆弱性修正やコード生成のような静的タスクに焦点を当てています。
また、Etherscanから抽出されたスマートコントラクトデータセットなどの専門的なベンチマークの使用は、ブロックチェーン技術の重要性と分散アプリケーションのセキュリティ対策の必要性を強調しています。これは、LLMベースのエージェントがソフトウェアセキュリティとメンテナンスの新たな課題に対処するための適応性と多様性を示しています。
これらの区別は、LLMベースのエージェントのより広範でインタラクティブなアプリケーションシナリオを反映しており、特定の構造に設計されたエージェントの場合、パブリックデータセットが適さないことも示しています。そのため、多くの自己収集されたベンチマークが生まれ、より柔軟性を提供しています。
E. 評価指標
ソフトウェアセキュリティとメンテナンスにおけるLLMsの評価指標は多岐に渡り、モデルまたはフレームワークのカバレッジ、効率、信頼性など様々な要素を考慮する必要があります。評価指標としては、成功率や合格率がLLMsのパフォーマンスを評価するために直接的に関連します。以下に、LLMsおよびLLMベースのエージェントの評価指標についての詳細を示します。
LLMsの評価指標
- 成功率(Success Rate) および 変化率(Change Rate):
- 多様な入力に直面した際のモデルの堅牢性を評価するために頻繁に使用されます。
- 時間オーバーヘッド(Time Overhead) および クエリ数(Query Number):
- 特定のタスクを実行する際のモデルの効率とリソース消費を評価します。
- ROC AUC、F1スコア、精度(Accuracy):
- 脆弱性を特定するモデルの能力を評価するために重要であり、特にバイナリ分類タスクで使用されます。
- コンパイル性(Compilability) および 妥当性(Plausibility):
- コード修正タスクで非常に一般的であり、生成されたソリューションが正確でデプロイ可能であることを保証します。
- BLEU および CodeBLEU:
- 生成されたコードの品質と人間らしさを評価し、モデルの能力とパフォーマンスが人間と比較可能であるかどうかを判断するのに役立ちます。
- ツリー編集距離(Tree Edit Distance) および テスト合格率(Test Pass Rate):
- ソフトウェア工学の専門分野でのLLMの応用効果を評価し、ソフトウェアセキュリティおよびメンテナンスによってもたらされる制約に対処します。
LLMベースのエージェントの評価指標
- 適切性(Appropriateness)、関連性(Relevance)、妥当性(Adequacy):
- これらは人間によって判断される基準であり、エージェントの評価には主観的な指標も含まれます。
LLMベースのエージェントは、LLMsと同様の評価指標を使用するだけでなく、より主観的な評価指標も導入しています。これらには、適切性、関連性、妥当性などの人間によって判断される基準が含まれます。全体として、エージェントの評価指標はLLMsよりも簡単で理解しやすい傾向があります。これは、エージェントが外部ツールの呼び出し頻度や計算オーバーヘッドなど、高レベルのタスクを処理するためです。
比較と分析
- 成功率およびタスク完了時間/コスト/効果:
- LLMsは個々のテスト方法の成功率を強調しますが、LLMベースのエージェントは全体的なタスク完了時間/コスト/効果に焦点を当てます。
- バイナリ分類指標:
- LLMsはROC、AUCおよびF1スコアのようなバイナリ分類指標を使用する一方で、エージェントは生成および検証の両方のフェーズで成功率と精度を強調し、包括的な評価を提供します。
- 時間コストとパフォーマンス:
これらの指標を比較することで、LLMsは個々のテスト方法の成功率を強調し、LLMベースのエージェントは全体的なタスク完了時間/コスト/効果に焦点を当てていることがわかります。LLMsは通常、バイナリ分類指標(例:ROC、AUC、F1スコア)を使用しますが、エージェントは生成および検証の両方のフェーズで成功率と精度を強調し、包括的な評価を提供します。
これにより、LLMベースのエージェントは、ソフトウェアセキュリティとメンテナンスの分野において、さらに多くの自律性と柔軟性をもたらし、タスクの実行効率と精度を向上させることができます。
X. DISCUSSION
A. Experiment Models
セクション3-8では、近年のソフトウェア工学におけるLLMs(大規模言語モデル)およびLLMベースのエージェント応用に関する研究をレビューし、紹介しました。これらの研究は異なる研究方向を持ち、分類と議論のために6つのサブトピックに分けました。
大規模言語モデルの進展に伴い、パブリックに登場したモデルが数千に達しています。さまざまな分野における大規模言語モデルの応用と、インテリジェントエージェントのコアとしての大規模言語モデルの使用法の理解をより直感的に行うために、全体で117本の論文をまとめ、ソフトウェア工学分野におけるLLMsの使用頻度について議論しました。
117本の論文をレビューした結果、筆者が実験で使用したモデルやフレームワークに焦点を当てました。この理由は、これらの論文が特定のドメインにおけるモデル性能を評価するテストを含んでいることが多いためです。例えば、コード生成におけるLLaMAの性能を評価するなどです。したがって、データ収集プロセスでは比較目的で使用されるモデルも含めました。これらのモデルは、それぞれの分野で最先端の能力を代表することが多いからです。
まとめると、117本の論文全体で79種類のユニークな大規模言語モデルが特定されました。これらのモデル名の使用頻度を直感的に表現するために、ワードクラウドで視覚化しました(図9)。この図からは、GPT-3.5、GPT-4、LLaMA2、およびCodexなどのモデルが頻繁に使用されていることがわかります。

クローズドソースのLLMsはローカルにデプロイすることはできないか、さらなるトレーニングができないものの、優れた能力を持つため、実験での比較やデータ拡張のために人気の選択肢となっています。例えば、GPT-4を使用して追加データを生成し、研究モデルフレームワークをサポートすることが一般的です。研究者はOpenAIのAPIを使用して初期テキストを生成し、ローカルでデプロイしたモデルを使用してさらに処理と最適化を行うことがあります[76][122][119][113]。
このように、ソフトウェア工学の特定の分野で優れた性能を持つ一般的大規模モデルを使用して開発を支援するか、評価基準として使用することが過去2年間で増加しています。また、これまでLLMsが触れたことのない分野でも、研究者はまずChatGPTモデルを参照し、新しいGPT-4でさまざまな性能実験を行っています[55][58][64]。
これらのモデルは、より大きなシステムに統合され、他の機械学習モデルやツールと組み合わせて使用されることができます。これらのモデルは自然言語応答を生成するために使用され、別のモデルが意図認識および対話管理を担当します。
セクション3-8では、近年のソフトウェア工学におけるLLMsおよびLLMベースのエージェント応用に関する研究をレビューし、紹介しました。これらの研究は異なる研究方向を持ち、分類と議論のために6つのサブトピックに分けて取り扱いました。

Modeling Analysis
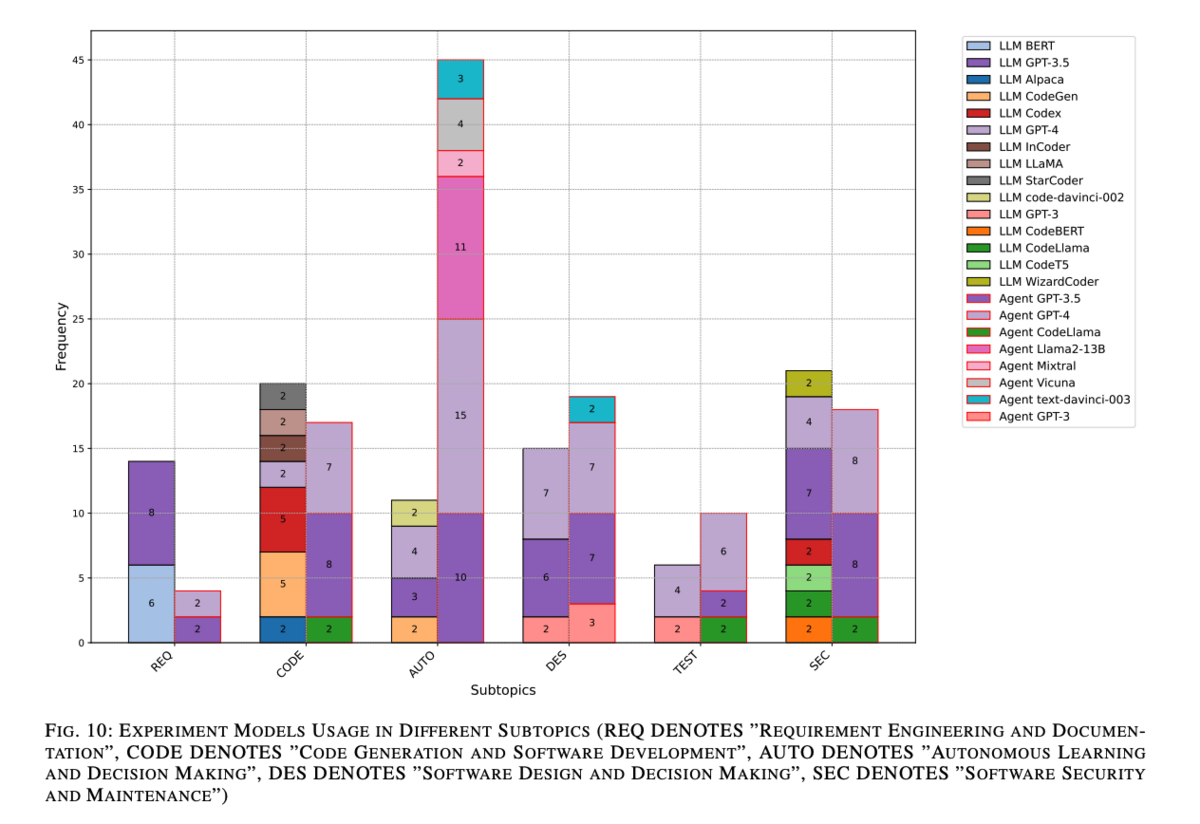
ワードクラウドはモデル使用頻度の概観を提供しますが、詳細な情報が欠けています。より深い洞察を得るために、グループ化された棒グラフと積み上げ棒グラフを組み合わせて、異なるサブトピックにわたる研究でのモデル使用を分析しました。対応する棒グラフは図10に示されています。この分析中、非常に多くのモデルが一度しか登場しないことが判明しました。これらを棒グラフに含めると全体の表現が煩雑になるため、一度しか登場しないモデルは除外し、残りのモデルの多用途性に焦点を当てました。各サブトピックの左側には、LLM関連の研究で使用されたモデルを描き、LLMベースのエージェント関連の研究で使用されたモデルを赤枠でハイライトしました。
図10を見てみると、「自律学習と意思決定」サブトピックでは、LLMベースのエージェント関連の研究で使用されたモデルの数が非常に多いことがわかります。具体的には、GPT-4およびGPT-3.5はそれぞれ18本の論文中10本および15本で使用されました。このサブトピックでは、GPT-3.5/4とLLaMA-2を研究および評価に使用することが一般的です。
特定分野でのモデルの使用
私たちの分析の中で、多くのLLMベースのエージェント研究が、エージェントの人間行動や意思決定の模倣能力や、一部の推論タスクの実行能力を評価していることがわかりました[103][111][108]。これらの研究ではローカルでのデプロイメントを必要としないため、特定の方向での最先端モデルの性能を評価することが主な目的となり、GPTファミリーのモデルが頻繁に使用されることとなります。例えば、[98]や[36]のようなフレームワークでは、GPT-4 APIを呼び出して言語エージェントがミスから学習するために口頭強化を使用しています。
さまざまなサブトピックでのモデル使用の違い
「自律学習と意思決定」サブトピックだけでなく、他のテーマでも、LLMベースのエージェントが使用するモデルの多様性(色数で表現)は比較的限られています。例えば、「要件工学とドキュメント化」サブトピックでは、実験に使用されたモデルはGPT-3.5およびGPT-4のみです。
モデル使用の背景分析
この現象の背後にある理由を分析するために、一度しか登場しなかったモデルが考慮されなかった要因や、インテリジェントエージェントに関する研究がそもそも少ないという要因を除外する必要があります。主な理由は、エージェントと大規模言語モデルの統合関係にあると考えられます。これら2つの技術の組み合わせは、特定のタスクや側面での大規模言語モデルの限界に対処することを目的としています。
インテリジェントエージェントは研究者により柔軟なフレームワークを設計し、大規模言語モデルを統合することを可能にします。これらのモデルは膨大なデータでトレーニングされており、強力な一般化能力を持つため、広範囲のタスクやドメインに適しています。したがって、研究者や開発者は同じモデルを使用して複数の問題に対処でき、多くのモデルを必要としないのです。
コード生成とソフトウェア開発での多様なモデル使用
コード生成[83][79]、テストケース生成[140][142]、およびソフトウェアセキュリティ[167][159]において、CodeLlamaを使用した例が見られます。これはLLaMAアーキテクチャに基づいて微調整および最適化されています。リリース時には、コード生成および理解タスクに最先端のモデルとみなされ、他のモデルと比較して優れた性能と潜在能力を示しました。
これらのモデルの成功した過去の応用と研究成果がその効果を証明し、研究者の信頼と依存を高めている可能性があります。特定のドメインで優れた性能を示すモデルと比較して、インテリジェントエージェント開発では、一般的な大規模モデルを使用することを好みます。これにより、エージェントのコアが優れたテキスト理解能力を持ち、さらに推論、計画、およびタスク実行が可能となります。
図10からも、コード生成およびソフトウェア開発の分野では多様なモデルが採用されていることが観察され、この分野が大きな注目を集め、コード生成タスクにおけるモデルの性能が優れていることが示唆されています。
B. Topics Overlapping
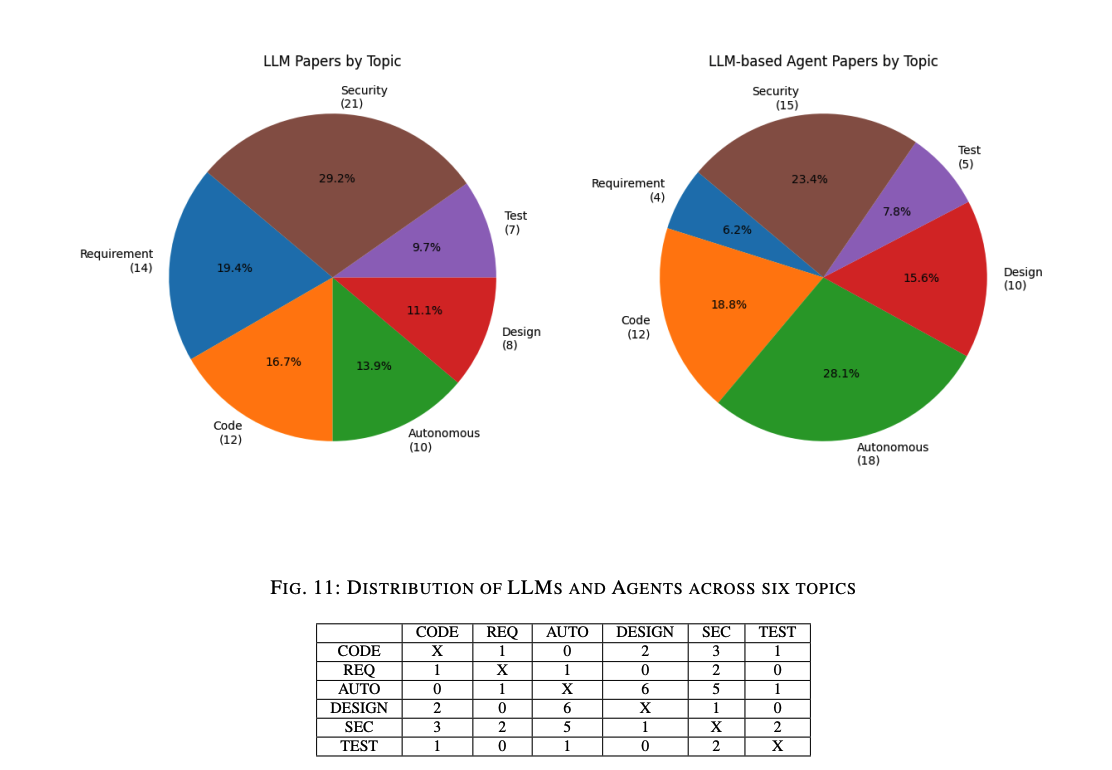
図11には、収集された文献が6つのテーマにわたってどのように分布しているかが示されています。LLMタイプの文献では、ソフトウェアセキュリティとメンテナンスのテーマが約30%を占めており、テストケース生成は10%未満です。この傾向は、LLMベースのエージェント文献にも反映されています。LLMベースのエージェントを使用して要件工学やテストケース生成に取り組む研究は比較的少ないです。
要件工学は、LLMベースのエージェントにとって新しい試みであり、エージェントフレームワーク全体を使用してテストケースを生成することは過剰であると考えられるためです。そのため、多くの研究は、エージェントフレームワーク内でLLMがもたらす変化、例えば自律的な意思決定能力やソフトウェアのメンテナンスおよび修正の能力を評価および探求する傾向があります。
重複するトピックの分析
表 XI には、複数のテーマにまたがる論文の数が示されています。例えば、5本の論文はソフトウェアセキュリティとメンテナンスおよび自律学習と意思決定の両方に分類されます。この2つのテーマは他のテーマとも最も多く重なっており、LLMおよびLLMベースのエージェント研究が広範であり、これらのタスクがコード生成、設計、およびテストなどのさまざまな分野からの知識と技術を統合する必要があることを示しています。
テーマ間の密接な関係
この大きな重複は、これらのテーマと他の分野との間の密接な関係を反映しています。例えば、自律学習と意思決定はしばしばモデルが自律的に学習し、意思決定ツリーを最適化する能力を含み、多くの具体的なソフトウェア工学タスクに適用される技術です。同様に、ソフトウェアセキュリティとメンテナンスは通常、自動コード生成ツールや自動テストフレームワークなど、複数の技術を組み合わせてセキュリティを強化する必要があります[71][80][83][102]。
相互補完的な技術と方法の統合
文献の重複は、ソフトウェア工学内での異なる研究分野からの方法や技術の統合がますます必要とされていることを強調しています。例えば、ソフトウェアセキュリティを確保するためには、セキュリティ対策だけでなく、コード生成、自動テスト、設計最適化技術の活用も必要です。同様に、自律学習と意思決定には、要件工学、コード生成、およびシステム設計の総合的な考慮が必要です。
さらに、ある技術や方法が強い共通性を持つことを示唆しています。例えば、LLMベースのエージェントは、自律学習と意思決定を通じてコード生成、テスト自動化、およびセキュリティ分析の能力を強化します。この技術の共有は、ソフトウェア工学内のさまざまな分野間の知識交換や技術の普及を促進します。
C. Benchmarks and Metrics
図12には、6つのトピックにわたる標準的なベンチマークの分布が示されています。実際には、使用されるベンチマークデータセットの数は図に示されたものよりもはるかに多く存在します。異なるソフトウェア工学のタスクには、それぞれ専用のベンチマークデータセットが評価とテストのために使用されます。
トピック別ベンチマークデータセット
- 要件工学:
- よく使用されるパブリックデータセット:
- MBPP および HumanEval: 以前のセクションで紹介されており、頻繁に使用されています。
- FEVER7: Agent関連の研究でよく使用されるデータセットです。例えば、[35]ではExpeLエージェントのファクト検証タスクの性能をテストするために使用されています。
- HotpotQA8: 知識集約的な推論および質問応答タスクのために頻繁に使用されます。
- Defects4J9: 脆弱性修正タスクでLLMが使用することが多いベンチマークデータセットです。このデータセットは、複数のオープンソースJavaプロジェクトからの835の実世界の欠陥を含み、自動プログラム修正技術の効果を評価するために使用されます。
区別と傾向
LLMおよびLLMベースのエージェントが使用するデータセットは、共通のパブリックデータセットを除いて異なります。例えば、Defects4JはLLM研究で広く使用されていますが、LLMベースのエージェント研究では比較的少ないです。これは、Defects4Jが主に単一のコード修正タスクを評価するのに使用され、多岐にわたるマルチタスクおよびリアルタイム要件には完全に一致しないためと考えられます。
新しいデータセットの紹介
- ConDefects:
- データ漏洩問題に対処し、より包括的な欠陥のローカリゼーションおよび修正評価を提供することを目的としています[142]。
図13には、LLMsおよびLLMベースのエージェントに使用されるトップ10の評価指標が示されています。この分析から、両者によって使用される評価方法がほぼ同じであることが明らかになりました。前のセクションでも述べたように、エージェントの場合、時間と計算資源の消費を考慮する必要があります。
評価指標の比較
- コード生成能力の評価:
- LLMsの生成コードの正確性やExact Matchの評価指標が多く使用されます[73][69][30]。
LLMsとLLMベースのエージェントにおけるソフトウェア工学アプリケーションの評価指標は、全体的に見て非常に類似しています。LLMsはしばしばコード生成のような静的タスクに焦点を当てる一方、LLMベースのエージェントは全体的なタスクの完了時間/コスト/効果に重きを置いています。
XI. 結論
この論文では、ソフトウェア工学におけるLLM(大規模言語モデル)およびLLMベースのエージェントの応用に関する包括的な文献レビューを行いました。ソフトウェア工学を以下の6つのトピックに分類しました:要件工学とドキュメント化、コード生成とソフトウェア開発、自律学習と意思決定、ソフトウェア設計と評価、ソフトウェアテスト生成、およびソフトウェアセキュリティとメンテナンス。各トピックについて、タスク、ベンチマーク、および評価指標を分析し、LLMとLLMベースのエージェントの違いとそれがもたらす影響について議論しました。
また、収集した117本の論文の実験に使用されたモデルの分析と議論も行いました。さらに、データセットおよび評価指標に関して、LLMとLLMベースのエージェントの統計と区別も提供しました。この分析により、LLMベースのエージェントの出現がさまざまなソフトウェア工学のトピックにわたる広範な研究および応用をもたらし、タスク、ベンチマーク、および評価指標の面で伝統的なLLMとは異なる強調を示していることが明らかになりました。
主な発見と結論
- タスクの違い:
- LLMsは主にコード生成やテストケース生成のような静的タスクに焦点を当てることが多いです。一方、LLMベースのエージェントは、自律的な意思決定やマルチエージェント協力のような動的および複雑なタスクにより重きを置いています。これは、エージェントがより包括的なタスク完了メトリクスとリアルタイムの調整を必要とするためです。
- ベンチマークの使用:
- 評価指標の多様性:
- 両アプローチとも成功率や精度のような基本的な定量的評価指標を使用しますが、LLMベースのエージェントは適切性や妥当性のような定性的指標も含むことが多いです。これにより、エージェントの高次のタスクに対する理解と適応性が評価されます。
- モデルの使用頻度と傾向:
- 多くのLLMベースのエージェント研究は、GPT-3.5やGPT-4のような最先端モデルを頻繁に使用し、人間の行動や意思決定の模倣能力を評価しています。また、LLaMAやCodeLlamaのようなモデルも、カスタムデータセットで微調整されて使用されています。
今後の展望
LLMおよびLLMベースのエージェントの研究は、さらなる進展と応用拡大が期待されます。特に、異なる分野からの知識統合が進むことで、クロスフィールドな応用が増加し、より強力なソフトウェアソリューションの開発が可能となるでしょう。要件工学やソフトウェアテスト生成のような新しい分野にも、LLMベースのエージェントの適用が拡大することが期待されます。